By Stan Seibert, Anaconda, Inc. & Nathan Greeneltch, Intel Corporation
TensorFlow is one of the most commonly used frameworks for large-scale machine learning, especially deep learning (we’ll call it “DL” for short). This popular framework has been increasingly used to solve a variety of complex research, business and social problems. Since 2016, Intel and Google have worked together to optimize TensorFlow for DL training and inference speed performance on CPUs. The Anaconda Distribution has included this CPU-optimized TensorFlow as the default for the past several TensorFlow releases. Performance optimizations for CPUs are provided by both software-layer graph optimizations and hardware-specific code paths. In particular, the software-layer graph optimizations use the Intel Math Kernel Library for Deep Neural Networks (Intel MKL-DNN), an open source performance library for DL applications on Intel architecture. Hardware specific code paths are further accelerated with advanced x86 processor instruction set, specifically, Intel Advanced Vector Extensions 512 (Intel AVX-512) and new instructions found in the Intel Deep Learning Boost (Intel DL Boost) feature on 2nd generation Intel Xeon Scalable processors. Let’s take a closer look at both optimization approaches and how to get these accelerations from Anaconda.
Hardware Level Deep Learning Optimizations
Hardware level optimizations use new x86 processor instructions to optimize performance for DL model training and inference. With the recently launched 2nd gen Intel Xeon Scalable processors, Intel introduced additional improvements to deep learning architecture directly on the CPU. This new hardware feature, called Intel DL Boost, includes enhanced optimizations for INT8 with a new vector instruction set called Vector Neural Network Instructions (VNNI). With the new instructions, the processor is able to complete more instructions per clock cycle, helping speed up execution. Figure 1 compares the inference throughput performance of CPU-optimized TensorFlow with an unoptimized stock version for popular image classification models. Switching to the CPU-optimized version results in an immediate performance boost of up to 11X on Resnet-101 model.1Inference Throughput Performance: CPU optimized TensorFlow compared with unoptimized (stock) TensorFlow
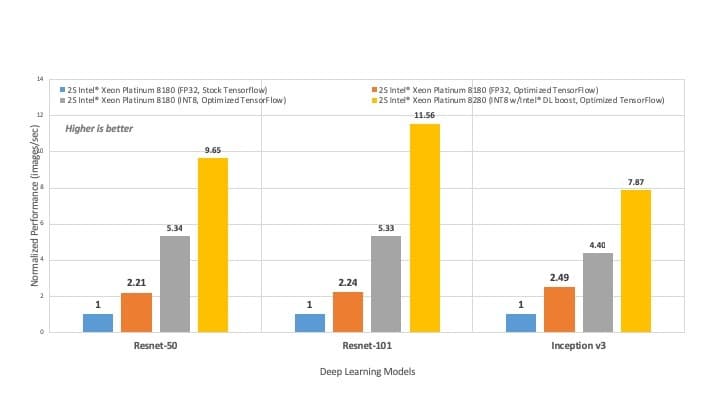
Figure 1: TensorFlow Inference throughput performance comparison on popular DL models. Note: TensorFlow 1.14 will provide the full performance optimizations for INT8 w/ Intel DL Boost. See test configuration details in Appendix below.
Software-layer Execution Graph Optimizations
A deep neural network written in a high-level language like Python is represented as an execution graph in TensorFlow. This graph can be optimized to accelerate the performance of the corresponding neural network. TensorFlow comes with many graph optimizations designed to speed up execution of deep learning workloads. Below are some of the optimizations occurring under the hood when executing on Intel CPUs.
Operator Fusions
CPU-optimized TensorFlow will overlap computation with memory accesses in order to conserve compute cycles. These fusion optimizations look for operators of different types (such as compute-bound, memory-bound, I/O bound, etc.) that occur in a sequence, and fuse them into a single operator. The example in Figure 2 fuses a Padding operator with a Convolution operator.
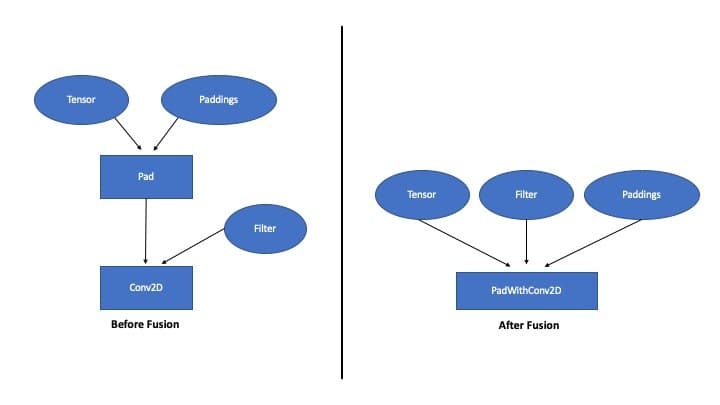
Figure 2: Graph Optimization Example: Before and After Fusion A Another example is fusing 2D Convolution with BiasAdd and ReLU operators. Intel’s graph optimization pass not only identifies patterns of two fusable operators, but can also combine sequences of more than two operators. One such example is an optimization to eliminate redundant transposes introduced by neural networks operating in different data formats. See Figure 3 for the fused version of the execution graph.
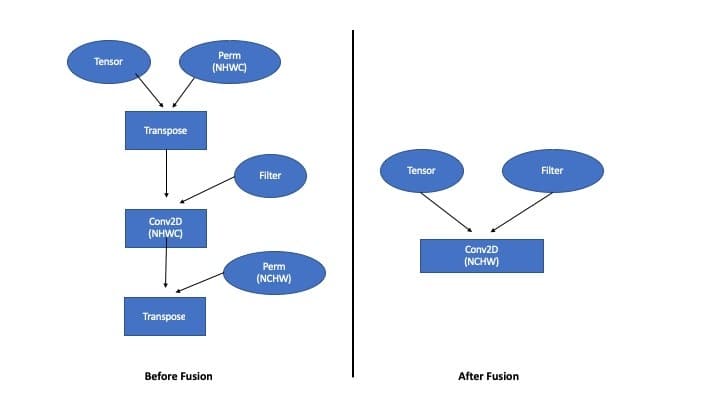
Figure 3: Graph Optimization Example: Before and After Fusion B Transpose is a memory-bound operation that wastes computational cycles in this particular case. As seen in Fig. 3, both these transposes can be made redundant if the 2D Convolution is made to operate directly on the data in its original layout. Filter Caching Convolutional neural networks will often have filters as inputs to the convolution operation. Intel MKL-DNN uses an internal format for these filters that is optimized for Intel CPUs and is different from the native TensorFlow format. When this filter is a constant, which is typically the case with inference, we can convert the filter from the TensorFlow format to Intel MKL-DNN format one time, cache it, and then reuse in subsequent iterations without needing to perform these format conversions again. This is merely a partial list of current performance strategies and optimizations Intel has added to TensorFlow. Work is ongoing and new optimizations will be added in the future. How to get the optimized package? Anaconda includes CPU-optimized TensorFlow binaries as part of its open source Distribution and its Enterprise software stack for easy install and package maintenance. So, no matter what complex problem you are trying to solve, you’ll have the right solution at your fingertips! To try the CPU-optimized TensorFlow through Anaconda package manager, run the following commands or add the package to your project in Anaconda Enterprise.
conda install tensorflow
You are now ready to take advantage of CPU-optimized TensorFlow for your project. APPENDIX Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks. Performance results are based on testing as of 4/5/2019 and may not reflect all publicly available security updates. No product or component can be absolutely secure. Configurations:
- TensorFlow Throughput Performance on Intel® Xeon® Processors tested by Intel as of 4/5/2019. 2 socket Intel® Xeon® Platinum 8180 Processor, 28 cores HT On Turbo ON Total Memory 384 GB (12 slots/ 32GB/ 2633 MHz), BIOS: SE5C620.86B.0D.01.0286.121520181757, CentOS 7.6, 4.19.5-1.el7.elrepo.x86_64, Deep Learning Framework 2 socket Intel® Xeon® Platinum 8280 Processor, 28 cores HT On Turbo ON Total Memory 384 GB (12 slots/ 32GB/ 2933 MHz), BIOS: SE5C620.86B.0D.01.0271.120720180605 (ucode:0x4000013),CentOS 7.6, 4.19.5-1.el7.elrepo.x86_64, Deep Learning Framework SW details: TensorFlow master https://github.com/tensorflow/tensorflow commit id 30f17fe3862fb855e6d9fa161a00f0a74d18857b using Synthetic data for FP32, INT8 w/ Batch Size = 128. (all INT8 related optimizations used in this measurement are expected to be available in TensorFlow 1.14 release) https://github.com/IntelAI/models/blob/87261e70a902513f934413f009364c4f2eed6642/models/image_recognition/tensorflow/resnet50/ https://github.com/IntelAI/models/blob/87261e70a902513f934413f009364c4f2eed6642/models/image_recognition/tensorflow/resnet101/ https://github.com/IntelAI/models/blob/87261e70a902513f934413f009364c4f2eed6642/models/image_recognition/tensorflow/inceptionv3/
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No product or component can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com. Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice Revision #20110804 Intel, the Intel logo, Intel Xeon, and Intel DL Boost are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others.