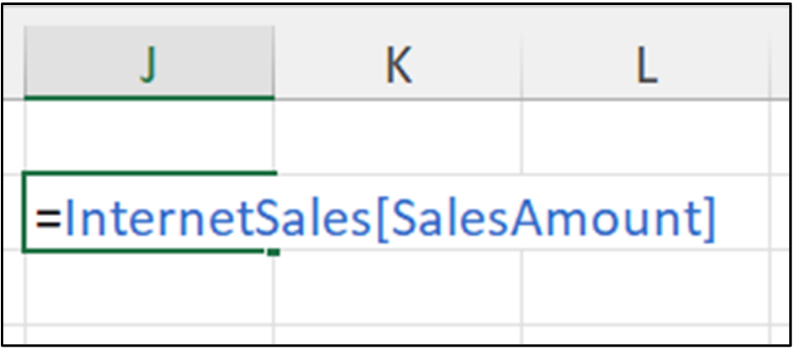


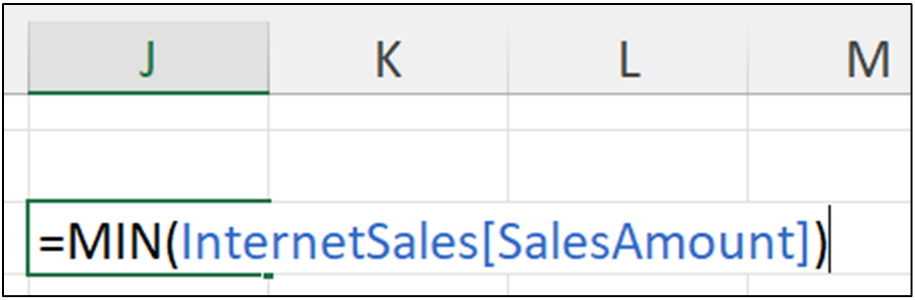
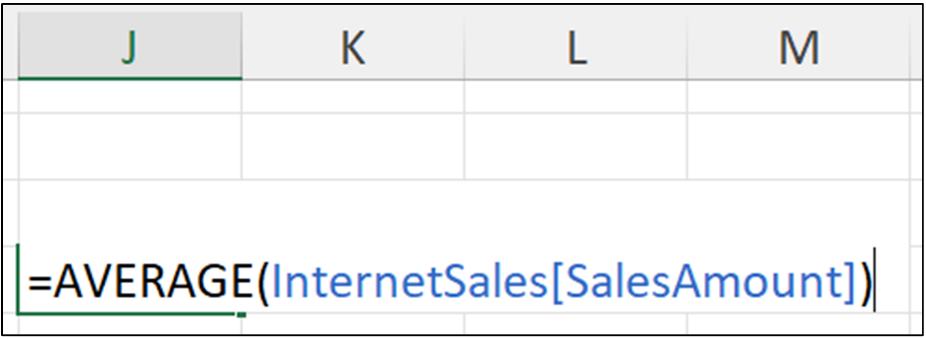
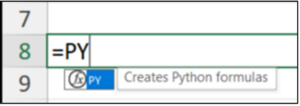



Running the above Python formula with <Ctrl+Enter> produces the following output:

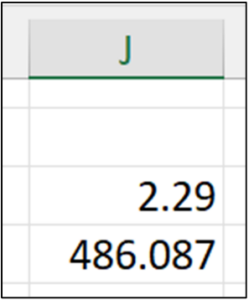
Fig 11 – Python code output for Fig 6
s the above illustrates, pandas code for calculating summary statistics is very similar to Excel code. While the above examples are simple, what’s important is the pattern of Python code you use when working with pandas Series objects.
In a later blog post, you will learn how to create new columns in a DataFrame from existing columns to provide more insight into the data. This process is known as feature engineering and builds on the skills you’ve learned in this post.
Describing a Numeric Column with Python
The pandas Series data type provides a handy method for calculating several summary statistics—the describe() method. The following code calls the describe() method on the SalesAmount column:

Running the Python formula will produce a new pandas Series object containing the calculated summary statistics. Using your mouse, hover over the card:
Fig 13 – Hovering your mouse over the card
Clicking the card will display the contents of the Series object:
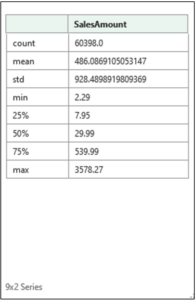
Fig 14 – The card for the describe() Series object
The Series object returned by the describe() method provides a wealth of information regarding the SalesAmount column and is quicker/easier than writing many Excel formulas to call the corresponding Excel functions:
- Of the 60,398 values, 50% are below $30 – despite the average value being $486.087.
- 75% of the values are below $540.
- The SalesAmount column is skewed with many small values and relatively few large values.
Many more methods are available for working with numeric pandas Series objects. See the online documentation for more information.
Working with Text Columns
Text is a common form of business data. Textual data comes in many forms—product names, geographies, addresses, etc. In Python the term string is used to refer to textual data.
Cleaning and transforming string data is very common. It’s likely that in your work as an Excel analyst, you’ve had to wrangle string data before it could be used in analyses. Some common examples of wrangling string data include:
- Transforming strings to be upper/lowercase
- Extracting substrings
- Replacing parts of strings
- Removing special characters
String Wrangling with Excel
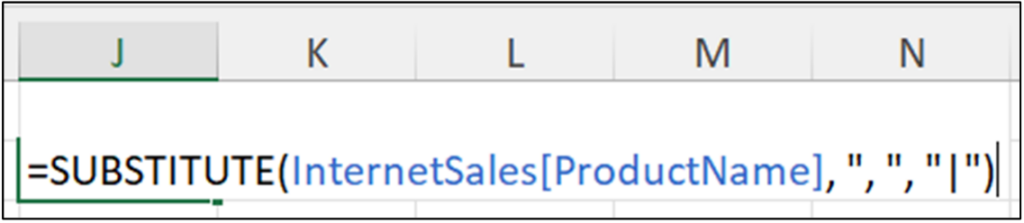
The following Excel code shows a common data wrangling scenario when working with string data—removing commas.
The ProductName column of the InternetSales table is string data that contains commas: