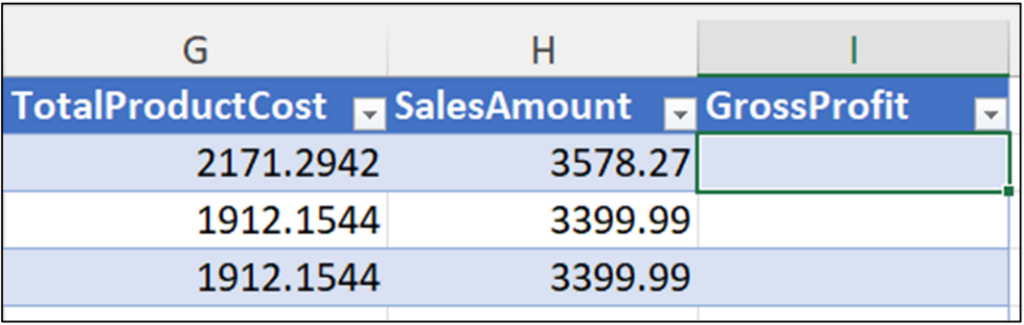
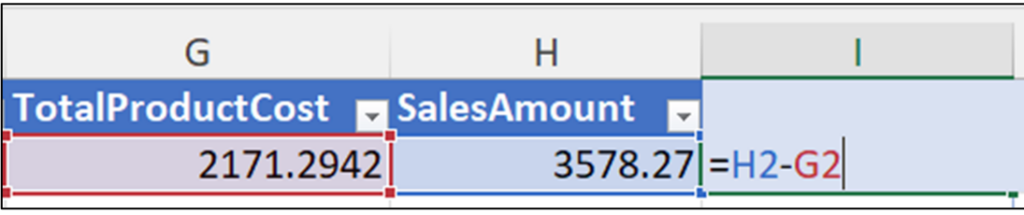
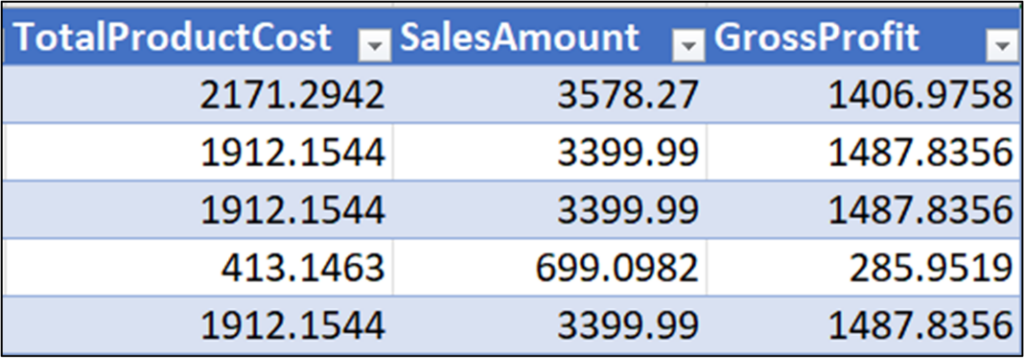
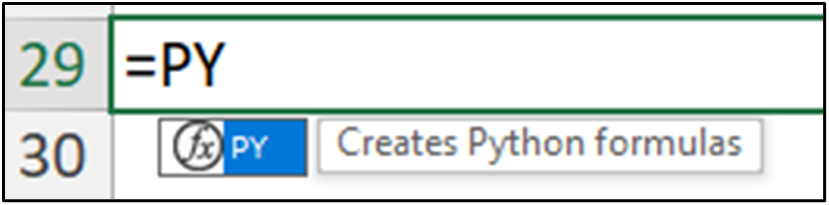
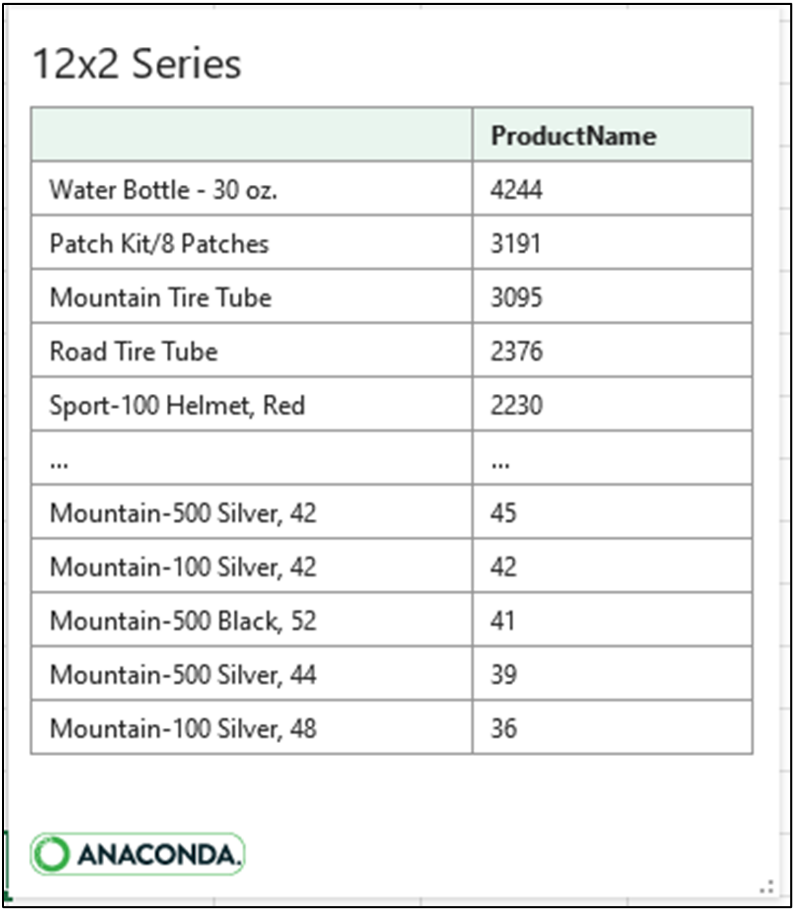
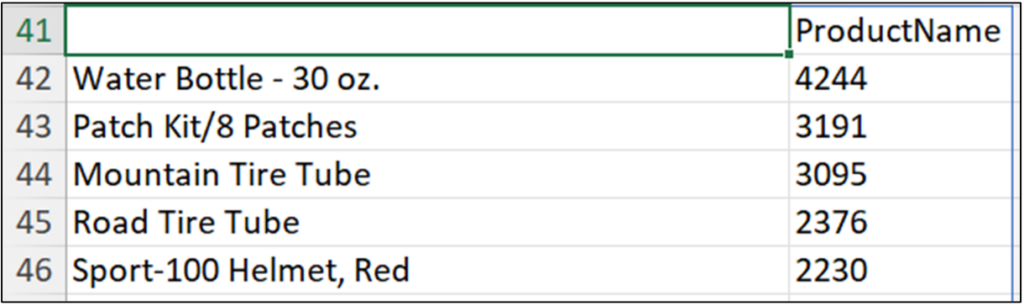
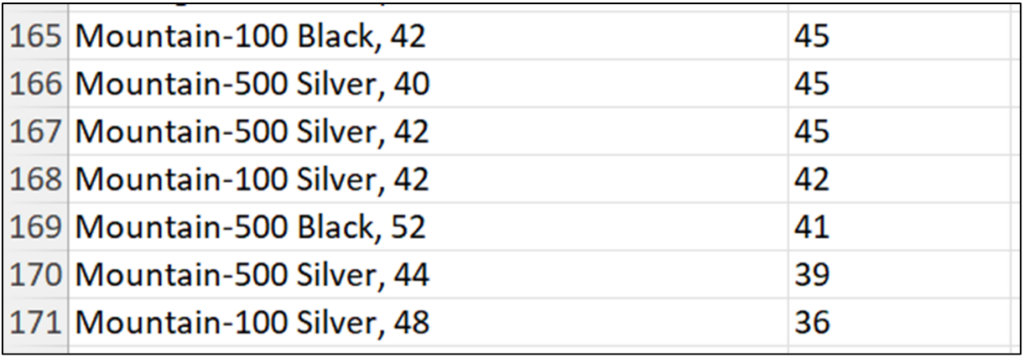
Fig 22 depicts how the cleaned ProductName data can now be used to analyze bicycle sales independent of bicycle color.
The pandas Series data type offers an extensive library for working with string data. Check out the online documentation for more information.
Note: The data cleaning example used in this post is common, but certainly not the only way to clean data. For more resources on data cleaning, check out these Anaconda courses: Introduction to pandas for Data Analysis and Data Cleaning with pandas.
What’s Next?
This blog post has been a brief introduction to data wrangling using pandas.
The pandas library offers a tremendous amount of capabilities for cleaning and wrangling data. This includes all the functionality you’ve used in Microsoft Excel in the past, and much more.
It is common for the bulk of data analysis Python code to be focused on acquiring, cleaning, and wrangling data. Building Python data-wrangling skills will serve you well.
The last post in this series will introduce you to another essential operation in crafting the best data analyses: joining tables of data (think VLOOKUP). Using Python to join tables of data provides you with three significant advantages in this regard:
- A complete set of various table join operations commonly used to prepare data for advanced analytics
- A greater level of control over how tables of data are joined
- Standardizing your joining logic so others can quickly reproduce it
If you want to learn more about working with data tables using pandas, take a beginner course for an Introduction to pandas for Data Analysis, and check out the official pandas user guide.
Disclaimer: The Python integration in Microsoft Excel is in Beta Testing as of the publication of this article. Features and functions are likely to change. Don’t hesitate to reach out if you notice an error on this page.
Bio
Dave Langer founded Dave on Data, where he delivers training designed for any professional to develop data analysis skills. Over the years, Dave has trained thousands of professionals. Previously, Dave delivered insights that drove business strategy at Schedulicity, Data Science Dojo, and Microsoft.