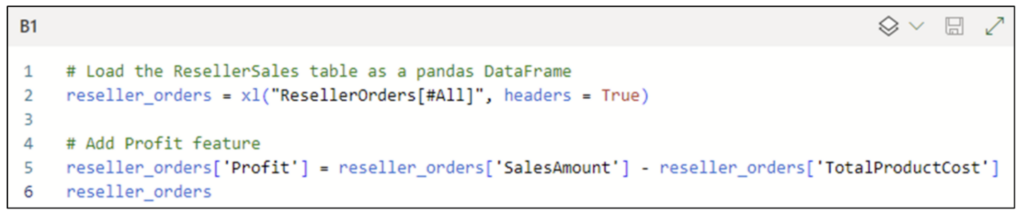
 Fig 04 – Executing the Python Code
The code shown in Fig 02 produces the following scatter plot:
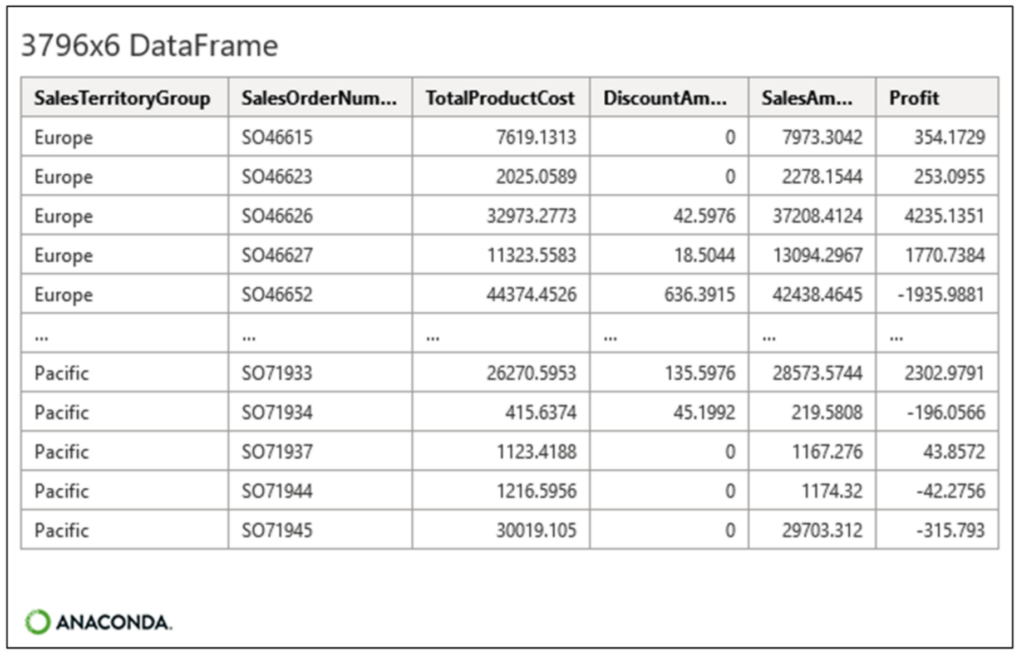
Fig 04 – Executing the Python Code
The code shown in Fig 02 produces the following scatter plot: 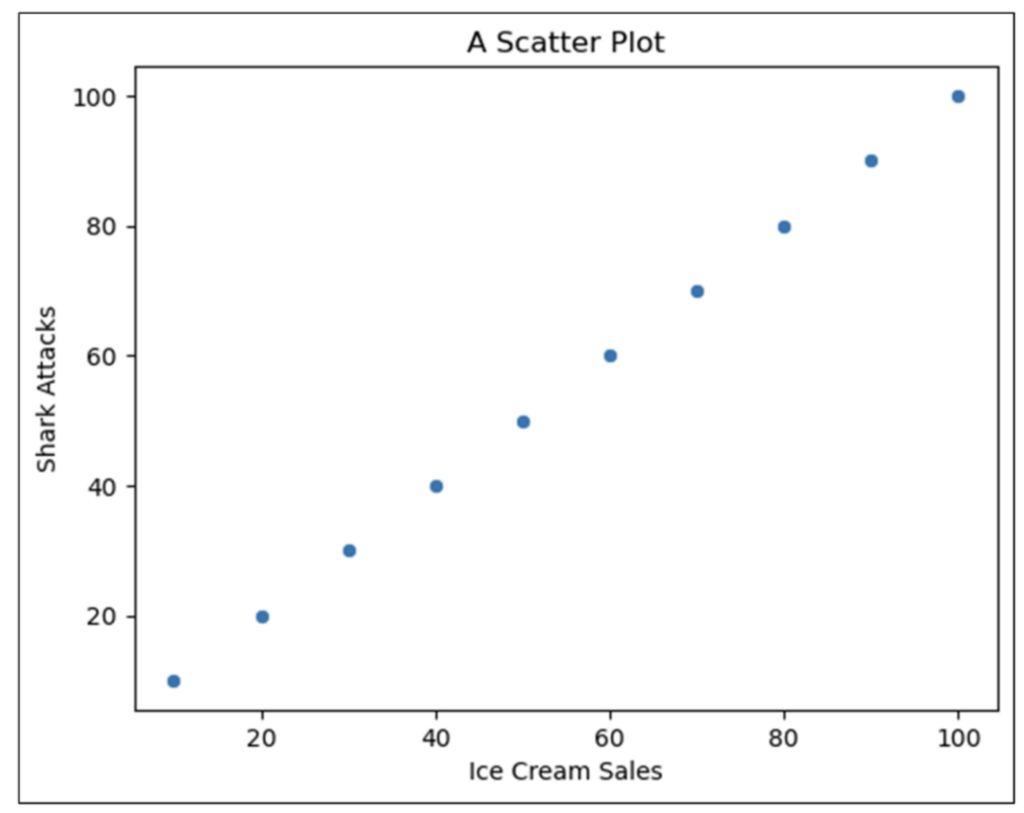
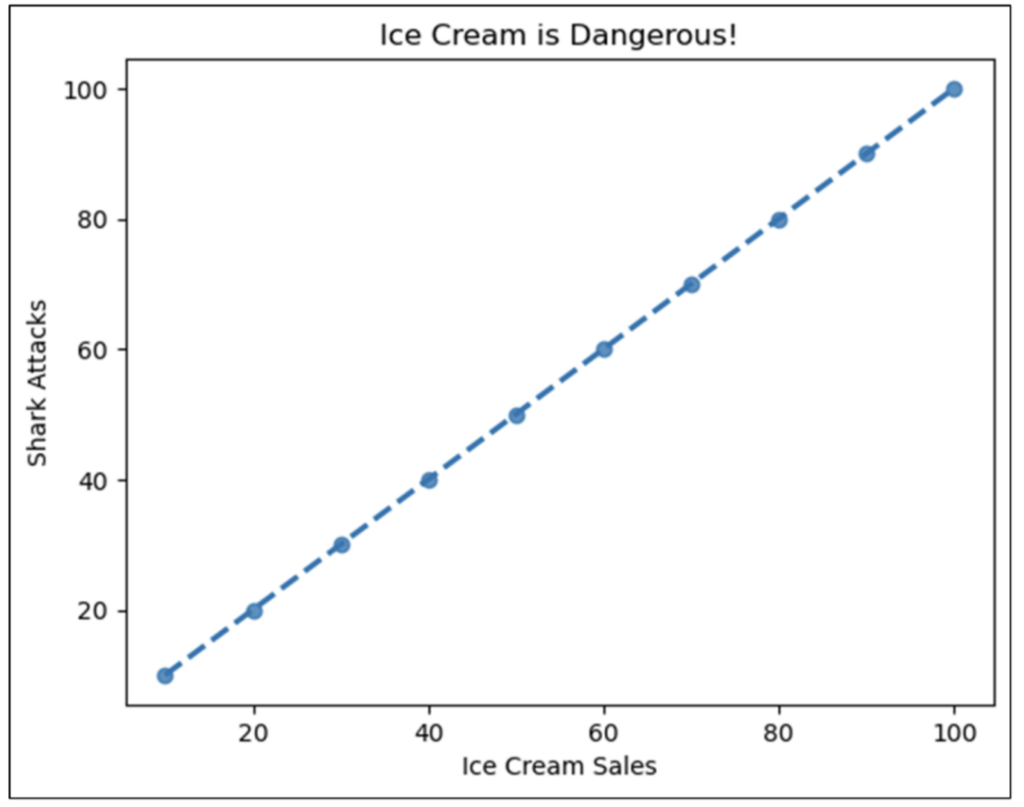
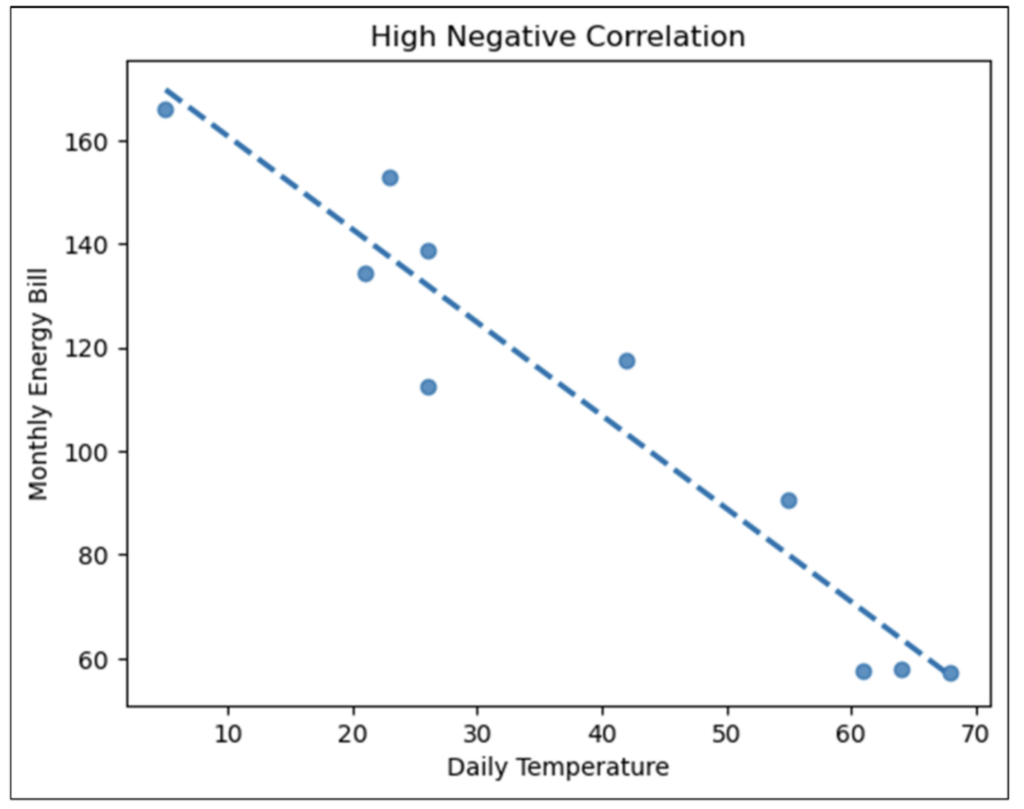

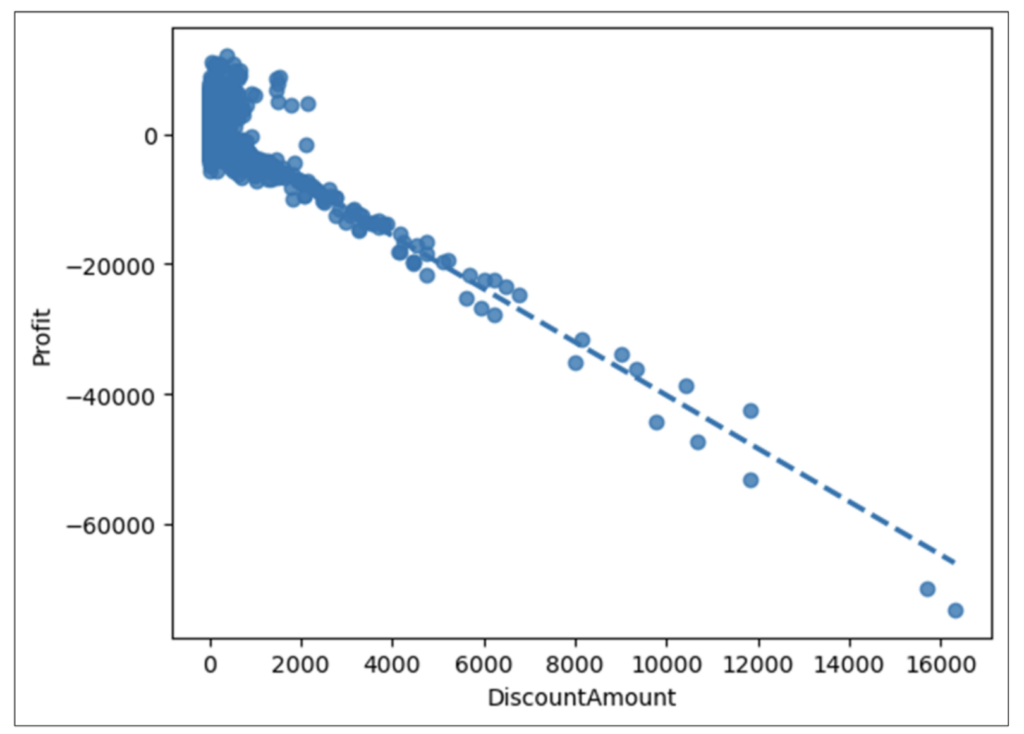
Examining Fig 15 reveals the following:
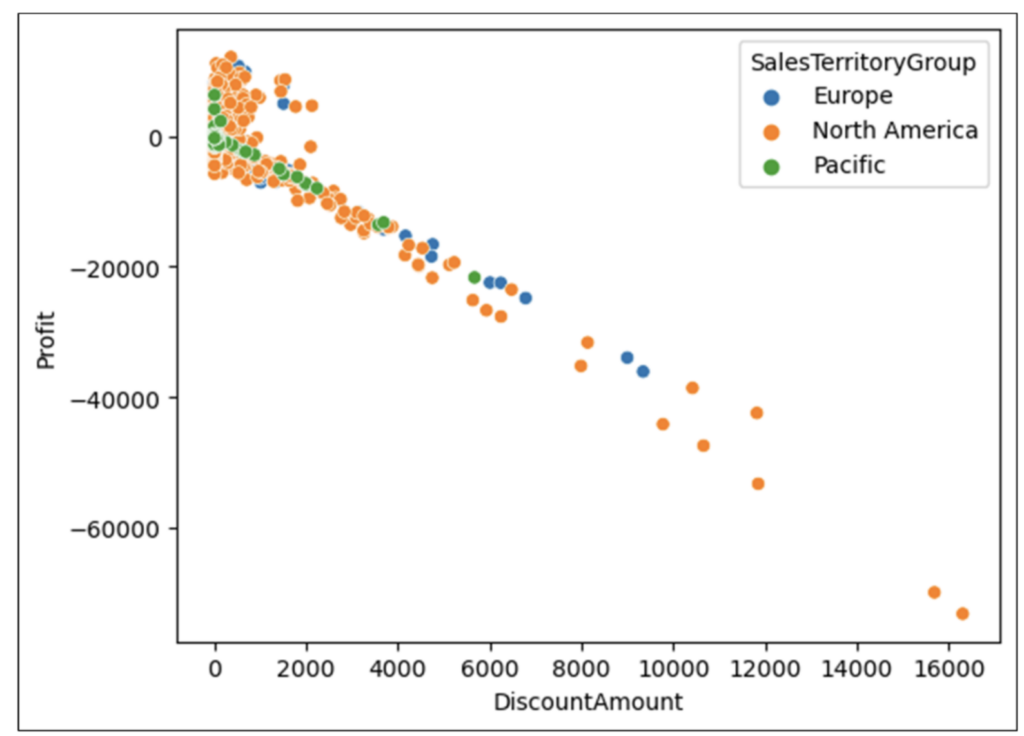
- Overall, there is a strong negative correlation between DiscountAmount and Profit.
- Based on the cloud of data points in the top left of the visualization, the predictive relationship isn’t very strong for very low DiscountAmount values.
- However, all orders appear to have negative Profit amounts when DiscountAmount exceeds approximately $2,500.
As discussed earlier, this correlation analysis shouldn’t assume that DiscountAmounts cause Profit. However, this highly predictive relationship is certainly worthy of further analysis.
Correlation of Profit by DiscountAmount and SalesTerritoryGroup
An example of drilling more into the correlation of Profit by DiscountAmount is investigating if certain geographies may exhibit higher/lower propensity for profitable/unprofitable orders.
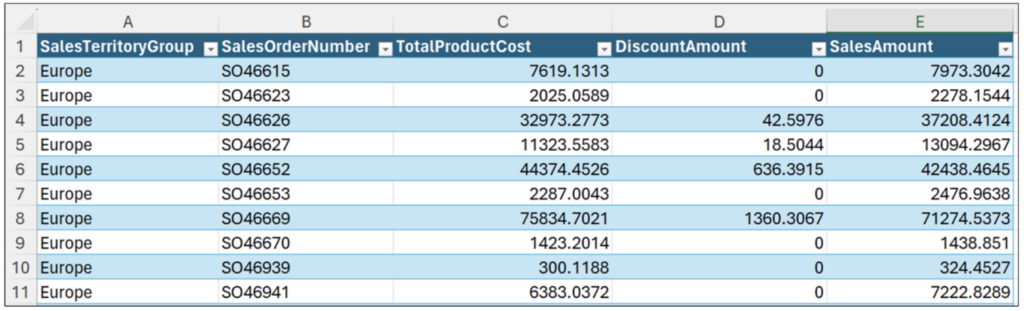
The reseller_orders DataFrame has a SalesTerritoryGroup column containing the following categorical values:
- Europe
- North America
- Pacific
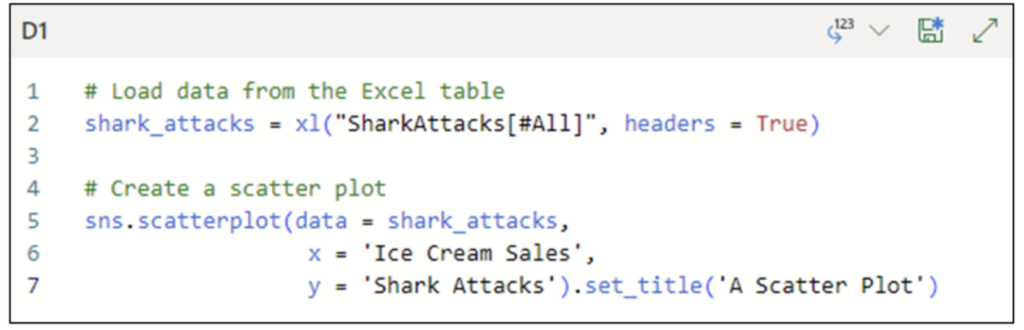
The following code creates a scatter plot of Profit by DiscountAmount and SalesTerritoryGroup:
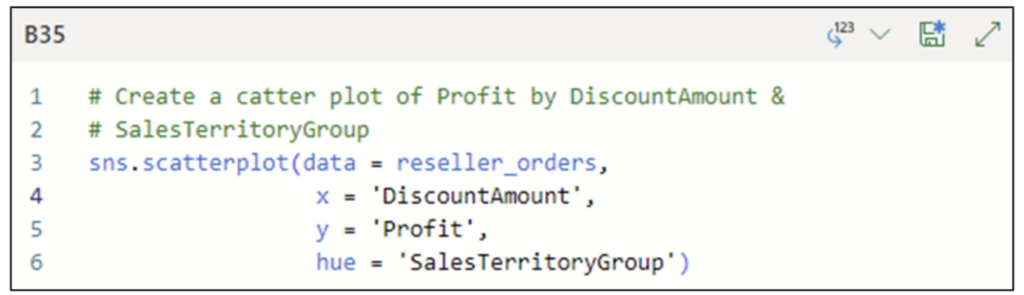
Fig 16 – Python Code for a Scatter Plot with Categorical Data
The code in Fig 16 uses the hue parameter to color code the scatter plot data points based on the values of SalesTerritoryGroup.
The Python Code Editor cell shown in Fig 16 is configured with the Convert to Excel values option. Executing the code produces the following visualization: