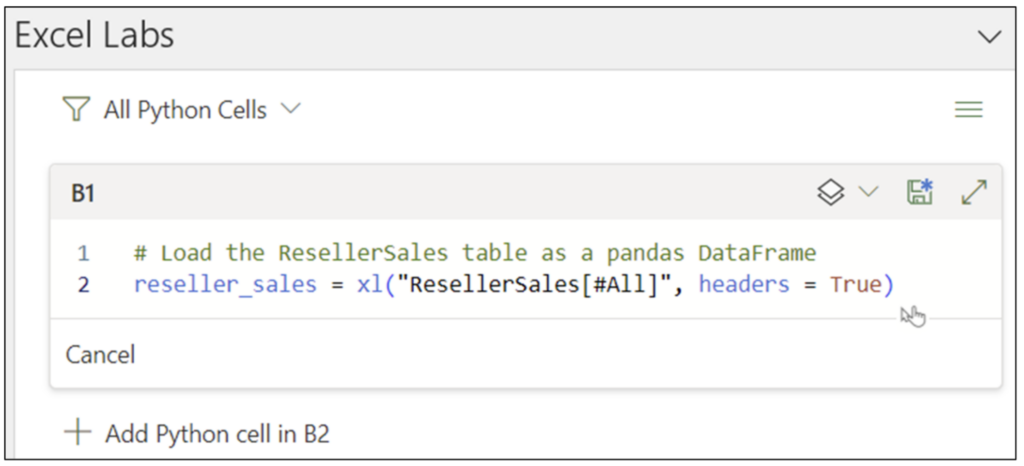
Note: While the above Python code is written using the Excel Labs Python Editor, this is not required.
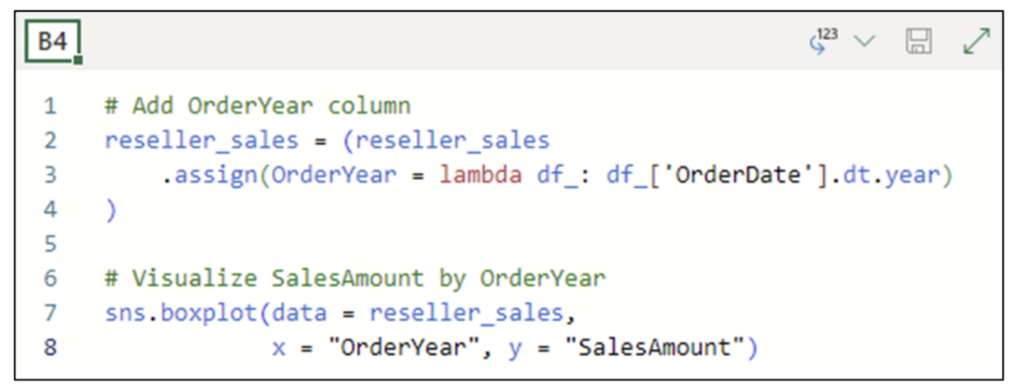
Clicking the disk icon in the Python Editor executes the Python code:
 Fig 08 – Python Code Execution
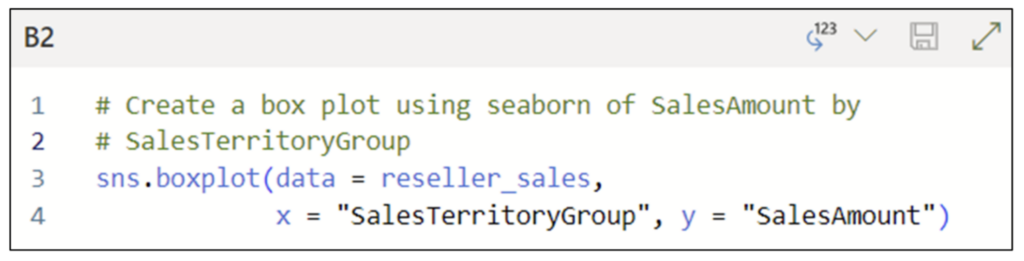
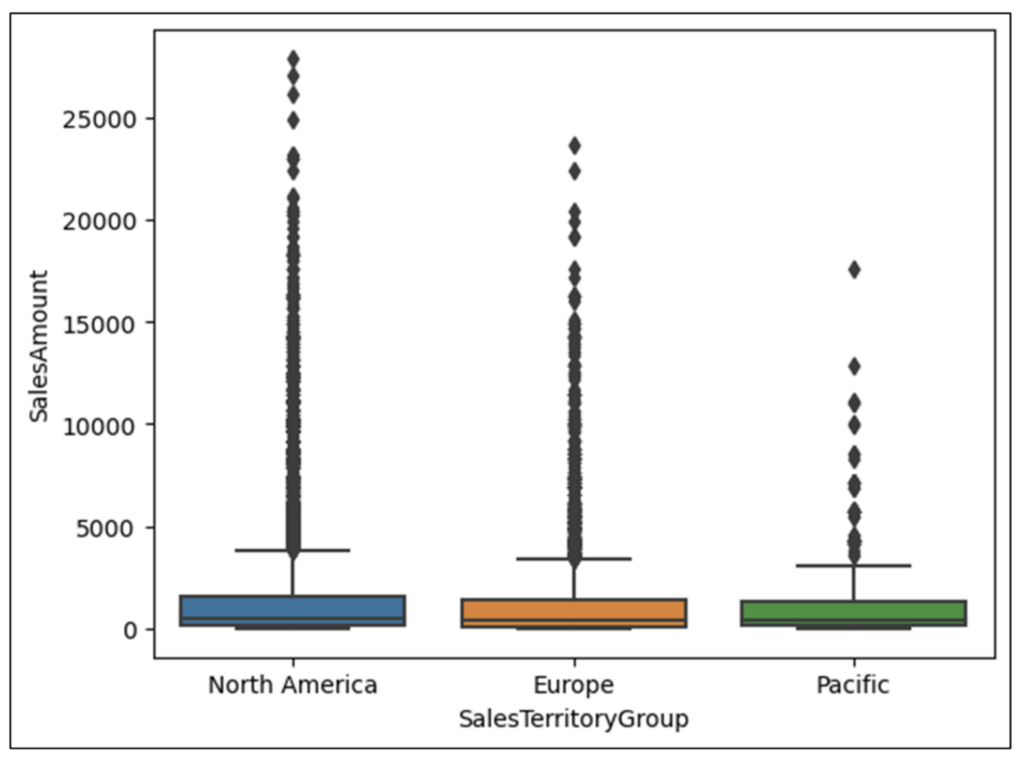
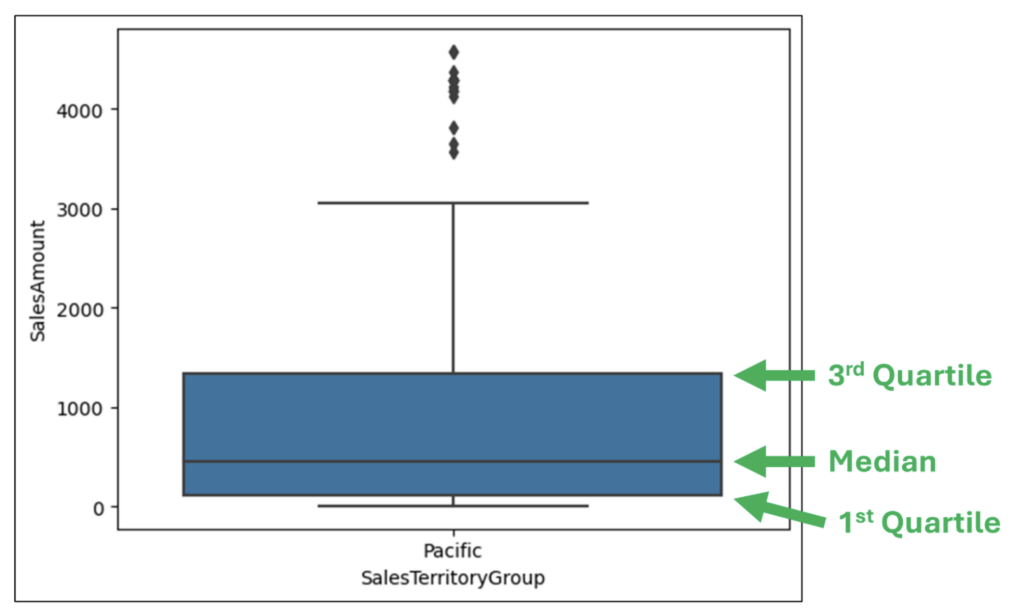
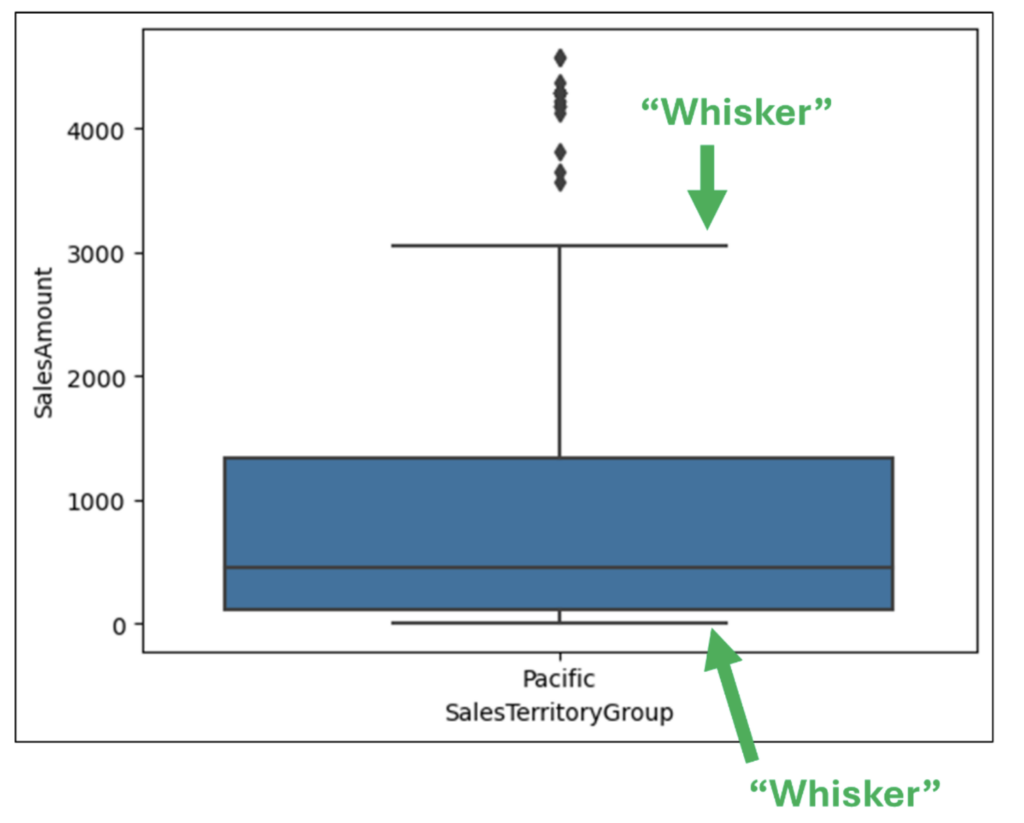
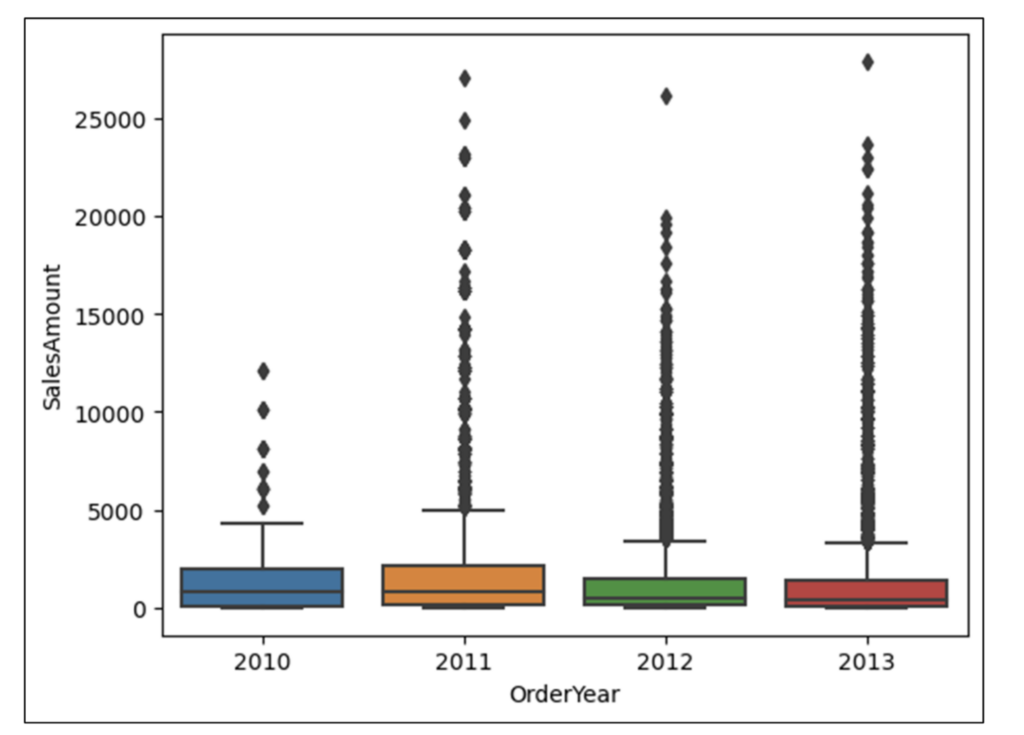
With the data loaded as a DataFrame, the following Python code uses the seaborn library to create a box plot using the SalesAmount and SalesTerritoryGroup columns:
Fig 08 – Python Code Execution
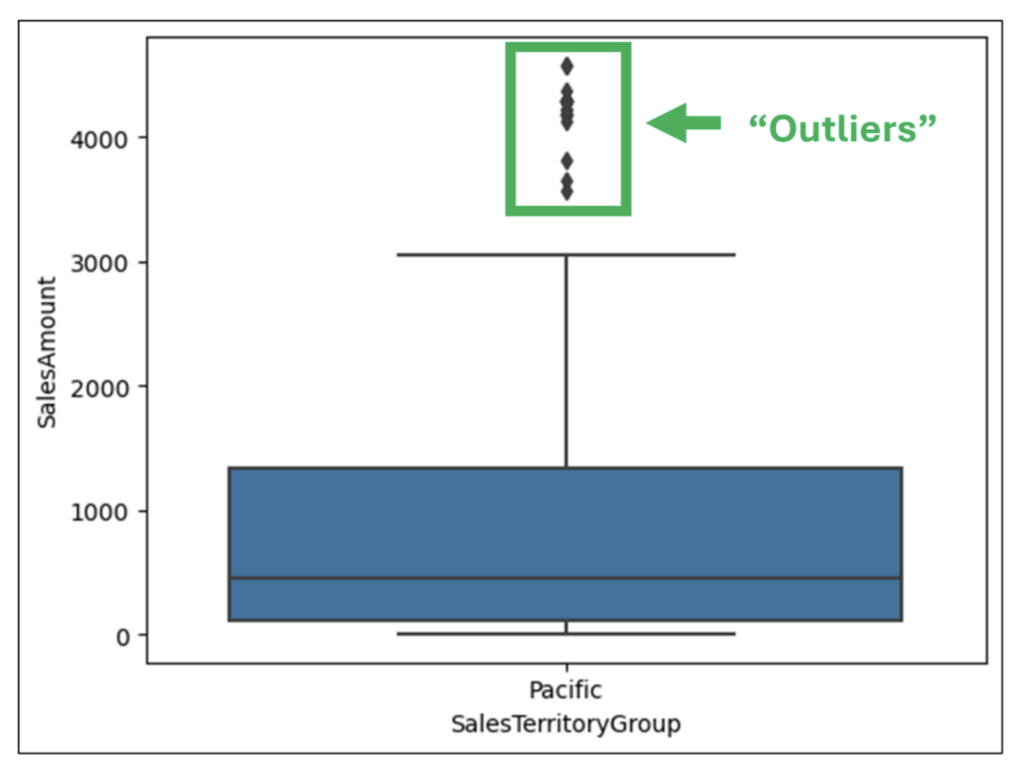
With the data loaded as a DataFrame, the following Python code uses the seaborn library to create a box plot using the SalesAmount and SalesTerritoryGroup columns:
Fig 08 – Python Code Execution
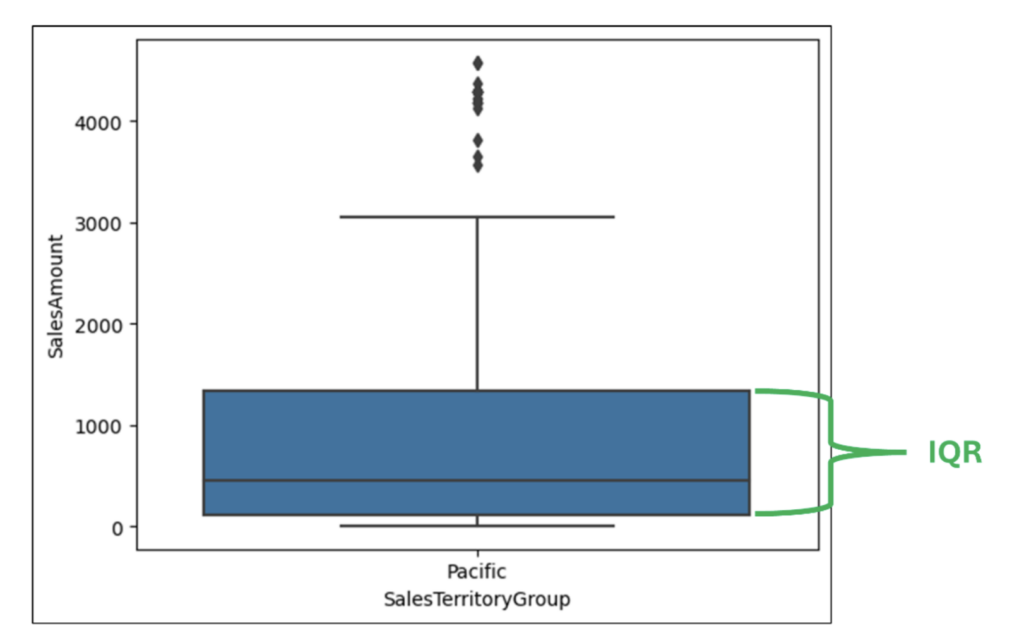
With the data loaded as a DataFrame, the following Python code uses the seaborn library to create a box plot using the SalesAmount and SalesTerritoryGroup columns: