In the ever-growing world of AI, local models have become a focal point, particularly for their advantages in privacy and safety. The capability to deploy and develop chatbots using local models is notably valuable for data security, privacy, and cost management. Mistral and Llama2 emerge as two of the best-performing open-source local large-language models (LLMs).
Llama2, presented by Meta in July this year, is a state-of-the-art collection of LLMs. It offers 7-billion, 13-billion, and 70-billion parameter models, all of which are available free of charge for research and commercial use. Mistral 7B, released in September by Mistral AI, is recognized as the most powerful LLM for its size. It outperforms Llama2 13B on all benchmarks, even though it has fewer parameters and is thus faster and easier to work with.
Leveraging these two foundational models, alongside a chat interface from the open-source project Panel, we will show you how easy it is to make AI chatbots with local models.
In this post, you’ll learn how to:
Use the Mistral 7B model
Add stream completion
Use the Panel chat interface to build an AI chatbot with Mistral 7B
Build an AI chatbot with both Mistral 7B and Llama2
Build an AI chatbot with both Mistral 7B and Llama2 using LangChain
Before we get started, you will need to install panel==1.3, ctransformers, and langchain. Note that if you are using a Nvidia GPU, please install ctransformers[cuda].
Now you are ready to go!
Getting started with Mistral
Let’s get started with a GGUF quantized version of Mistral 7B Instruct and use one of the AutoClasses `AutoModelForCausalLM` to load the model. AutoClasses can help us automatically retrieve the model given the model path. AudoModelForCausalLM is one of the model classes with causal language modeling and that’s what we need for our Mistral 7B Instruct model.
Python
# Source: https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUFfrom ctransformers import AutoModelForCausalLM# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF",model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",model_type="mistral",gpu_layers=50)print(llm("AI is going to"))
Adding Stream Completions
With the above example, when we run model inference, it returns one single response when the entire answer is generated. This can be slow when we are generating long responses. And, when we are in a chat interface, it might be more natural to see the model `typing` the response one word at a time. That’s why we sometimes might want to `stream` the response while it’s being generated. To do this, we simply add `stream=True` during our call to the model.
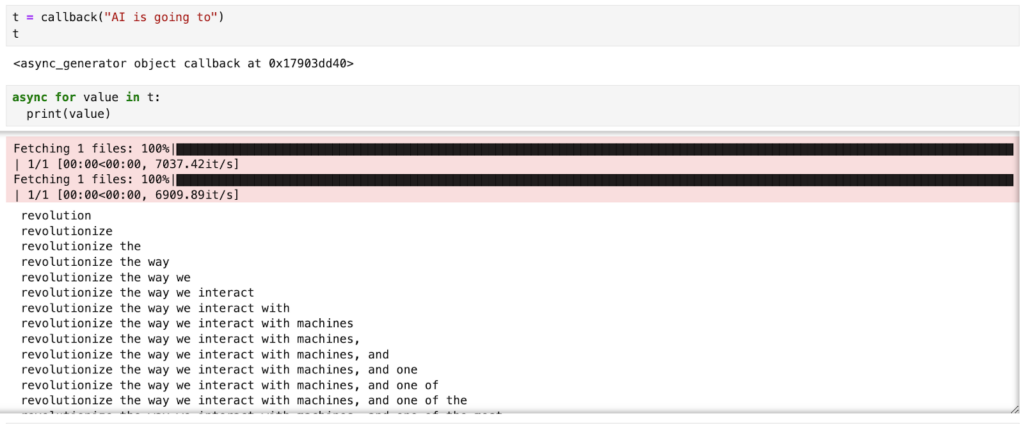
To speed up the model response, we use `async` to allow the IO task to happen in the background so that the computer can perform other tasks while waiting for the model response.
The result of the `callback` function is an async generator, which allows us to iterate over data that comes asynchronously. If we print out the values, we can see how the response tokens get generated one at a time.
Building our first chatbot with Mistral 7B
How do we wrap this model into a chat interface? Panel makes it super easy to build a chatbot with just five lines of code!
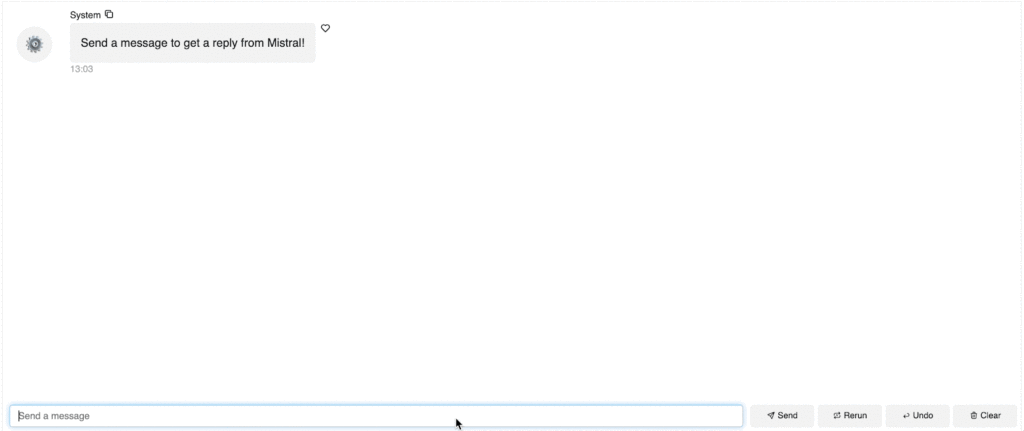
We first define a ChatInterface widget: chat_interface = pn.chat.ChatInterface(callback=callback, callback_user=”Mistral”). This widget handles all the UI and logic of our chatbot. Note that we need to define how the system responds in the `callback` function, which is what we have just defined above.
Let’s start the chatbot with a system message “Send a message to get a reply from Mistral!” so that the users have clear instructions on what to do.
And finally chat_interface.servable() ensures we can serve the app either locally or on a cloud. To serve the app, simply save the code below as a standalone Python file app.py or a Jupyter Notebook file app.ipynb, and run `panel serve app.py` or `panel serve app.ipynb`.
Note: An async callback isn’t required, but it does improve the user experience.
If you are interested in learning how to build AI chatbots with OpenAI API and LangChain, check out our previous blog post.
Python
"""Demonstrates how to use the ChatInterface widget to create a chatbot usingMistral thru CTransformers."""import panel as pnfrom ctransformers import AutoModelForCausalLMpn.extension()asyncdefcallback(contents:str,user:str,instance: pn.chat.ChatInterface):if"mistral"notin llms: instance.placeholder_text="Downloading model; please wait..." llms["mistral"]= AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF",model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",gpu_layers=1,) llm = llms["mistral"] response =llm(contents,stream=True,max_new_tokens=1000) message =""for token in response: message += tokenyield messagellms ={}chat_interface = pn.chat.ChatInterface(callback=callback,callback_user="Mistral")chat_interface.send("Send a message to get a reply from Mistral!",user="System",respond=False)chat_interface.servable()
Building our second chatbot with both Mistral 7B and Llama2 7B
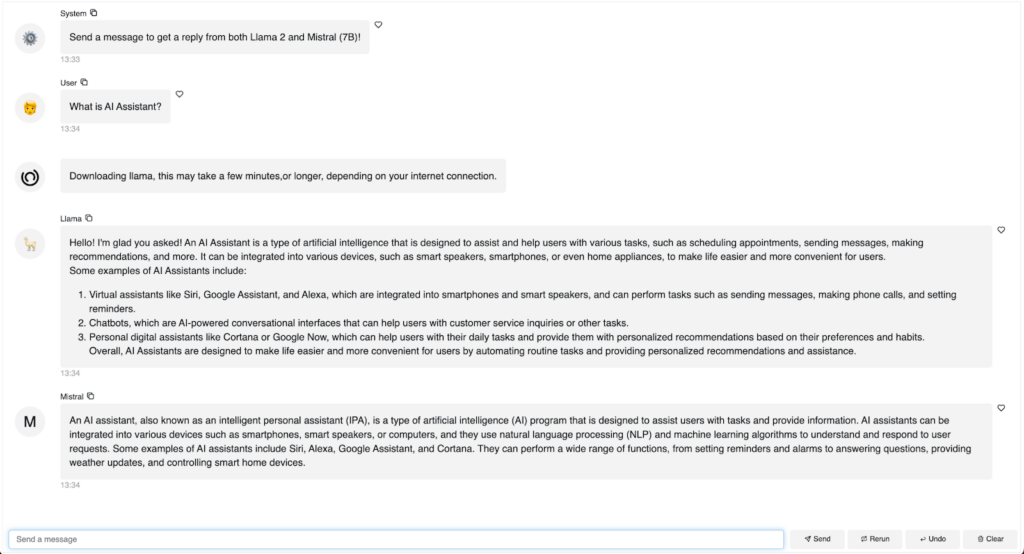
Can we add responses from another model? Can we compare responses from different models? Yes, We absolutely can! Here is an example:
We define model information including model name, model path, and model file in a dictionary MODEL_ARGUMENTS
Then in a for-loop, we pass in each model separately and send each model’s response to the chat interface.
Python
"""Demonstrates how to use the ChatInterface widget to create a chatbot usingLlama2 and Mistral. """import panel as pnfrom ctransformers import AutoModelForCausalLMpn.extension()MODEL_ARGUMENTS ={"llama":{"args":["TheBloke/Llama-2-7b-Chat-GGUF"],"kwargs":{"model_file":"llama-2-7b-chat.Q5_K_M.gguf"},},"mistral":{"args":["TheBloke/Mistral-7B-Instruct-v0.1-GGUF"],"kwargs":{"model_file":"mistral-7b-instruct-v0.1.Q4_K_M.gguf"},},}asyncdefcallback(contents:str,user:str,instance: pn.chat.ChatInterface):for model in MODEL_ARGUMENTS:if model notin pn.state.cache: pn.state.cache[model]= AutoModelForCausalLM.from_pretrained(*MODEL_ARGUMENTS[model]["args"],**MODEL_ARGUMENTS[model]["kwargs"],gpu_layers=1,) llm = pn.state.cache[model] response =llm(contents,max_new_tokens=512,stream=True) message =Nonefor chunk in response: message = instance.stream(chunk,user=model.title(),message=message)chat_interface = pn.chat.ChatInterface(callback=callback)chat_interface.send("Send a message to get a reply from both Llama 2 and Mistral (7B)!",user="System",respond=False,)chat_interface.servable()
After running `panel serve app.py` or `panel serve app.ipynb`, you can chat with both Llama2 and Mistral and directly compare their responses.
Building our third chatbot with Mistral 7B and Llama2 7B using LangChain
Can we build the same chatbot with LangChain? Yes! LangChain is a framework for developing LLM applications that many people find useful.
LangChain provides a CTrasnformers wrapper, which we can access with from langchain.llms import CTransformers. We can then use the CTransformers unified interface to load our two models.
PromptTemplate helps us define reusable templates for generating prompts to send to the language model. We define our prompt in the prompt variable.
We use an LLMChain to chain the prompt with a language model. Specifically, it formats the prompt template using provided input values, passes the formatted prompt to the language model, and returns the output.
Python
"""Demonstrates how to use the ChatInterface widget to create a chatbot usingLlama2 and Mistral."""import panel as pnfrom langchain.chains import LLMChainfrom langchain.llms import CTransformersfrom langchain.prompts import PromptTemplatepn.extension()MODEL_KWARGS ={"llama":{"model":"TheBloke/Llama-2-7b-Chat-GGUF","model_file":"llama-2-7b-chat.Q5_K_M.gguf",},"mistral":{"model":"TheBloke/Mistral-7B-Instruct-v0.1-GGUF","model_file":"mistral-7b-instruct-v0.1.Q4_K_M.gguf",},}llm_chains ={}TEMPLATE ="""<s>[INST] You are a friendly chat bot who's willing to help answer the user:{user_input} [/INST] </s>"""asyncdefcallback(contents:str,user:str,instance: pn.chat.ChatInterface): config ={"max_new_tokens":256,"temperature":0.5}for model in MODEL_KWARGS:if model notin llm_chains: instance.placeholder_text=(f"Downloading {model}, this may take a few minutes,"f"or longer, depending on your internet connection.") llm =CTransformers(**MODEL_KWARGS[model],config=config) prompt =PromptTemplate(template=TEMPLATE,input_variables=["user_input"]) llm_chain =LLMChain(prompt=prompt,llm=llm) llm_chains[model]= llm_chain instance.send(await llm_chains[model].apredict(user_input=contents),user=model.title(),respond=False,)chat_interface = pn.chat.ChatInterface(callback=callback,placeholder_threshold=0.1)chat_interface.send("Send a message to get a reply from both Llama 2 and Mistral (7B)!",user="System",respond=False,)chat_interface.servable()
Run `panel serve app.py` or `panel serve app.ipynb` and we will get a chatbot interacting with both Llama2 and Mistral using LangChain!
Conclusion
In this blog, we demonstrated how to run a Mistral 7B instruct model, how to improve performance with stream completion and an async generator, how to build a chatbot using Panel’s chat interface widget, how to build a chatbot with both Mistral 7B and Llama2 7B, and finally how to build this chatbot using LangChain. We hope you found value in this blog. Happy coding!
Note:
All of these tools are open source and free for everyone to use, but if you’d like some help getting started from Anaconda’s AI and Python app experts, reach out to [email protected]!
 The result of the `callback` function is an async generator, which allows us to iterate over data that comes asynchronously. If we print out the values, we can see how the response tokens get generated one at a time.
The result of the `callback` function is an async generator, which allows us to iterate over data that comes asynchronously. If we print out the values, we can see how the response tokens get generated one at a time.