As enterprises transition from pilot projects to production-grade generative AI systems, robust architecture becomes essential. They must consider a range of factors: choosing the right model, ensuring scalability, security, observability, and governance at every layer of the stack.
Below, we share a direct excerpt from Generative AI in Action by Amit Bahree (Manning, 2024), outlining foundational architectural principles for GenAI applications—from working with enterprise data, to using retrieval-augmented generation (RAG), to GenAI architecture principles.
The following text is excerpted with permission.
Your enterprise has taken a critical step toward using generative AI to drive innovation and efficiency. However, understanding what comes next is crucial to maximizing the benefits and mitigating the risks of this advanced technology.
To get started implementing an Enterprise ChatGPT check outthis high-level overview of what a typical workflow in an enterprise might look like, in Figure 1.
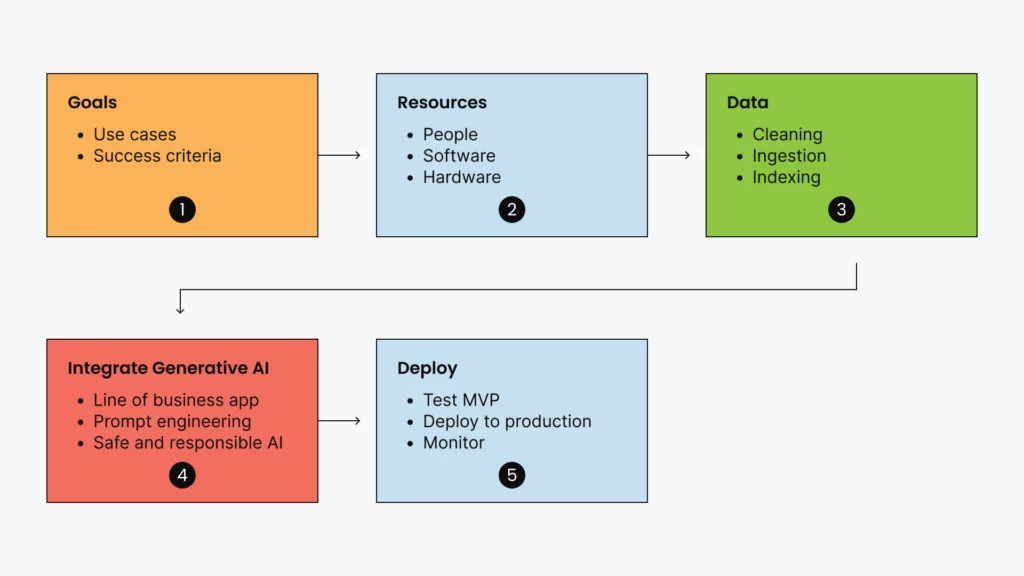
You should start by setting clear goals for your chatbot. What challenges do you want to address with generative AI? How can it help you the most? This could be anything from creating content for marketing to enhancing customer service with chatbots, forecasting for business plans, or even innovating new products or services. An Enterprise ChatGPT is deployed and runs in an enterprise environment, using internal and proprietary data, and only authorized users can access it.
You’ll need to ensure that you have the necessary resources available, that is, people with the right competencies, a suitable hardware and software framework, defining indicators of success, and the appropriate governance and ethics principles in place.
Then, consider the data. An enterprise chatbot would need access to relevant, high-quality enterprise data that the user can employ. This data needs to be ingested and indexed to help answer proprietary questions. Before that, the data must be managed properly, ensuring privacy and legal compliance. Remember, the quality of the data fed will influence the output quality.
Next, you’ll need to integrate the enterprise chatbot into the line of business applications that address the use case and the problem you are trying to address. As an enterprise, you will also want to address the risks associated with generative AI and implement corporate guidance around safety and responsible AI.
Lastly, although you might be ready to deploy in production, implementing generative AI is not a one-time event but a journey. It requires continuous monitoring, testing, and fine-tuning to ensure it works optimally and responsibly. It’s a good idea to start with smaller, manageable projects and gradually scale up as you gain more confidence and expertise in handling this powerful technology.
Adopting generative AI is a significant commitment that could transform your enterprise, but it requires careful planning, appropriate resources, ongoing monitoring, and an unwavering focus on ethical considerations. With these in place, your enterprise can reap the numerous benefits of generative AI.
Chatting with Your Data
Utilizing large language models (LLMs) for a chat-with-data implementation is a promising strategy uniquely suitable for enterprises seeking to harness the power of generative artificial intelligence (AI) for their specific business requirements. By synergizing the LLM capabilities with enterprise-specific data sources and tools, businesses can forge intelligent and context-aware chatbots that deliver invaluable insights and recommendations to their clientele and stakeholders.
At a high level, there are two ways to chat with your data using an LLM—one is by employing a retrieval engine as implemented using the retrieval-augmented generation (RAG) pattern, and another is to custom-train the LLM on your data. The latter is more involved and complex and not available to most users.
This chapter builds on the RAG pattern from the last chapter used to enhance LLMs with your data, especially when enterprises want to implement it at the scale for production workloads. When enterprises integrate their data using a RAG pattern with LLMs, they unlock many advantages, enhancing the functionality and applicability of these AI systems in their unique business contexts. The chapter outlines how these are different and, in many cases, better than larger context windows. Let’s start by identifying the advantages enterprises can get when wanting to bring in their data.
Advantages to Using Your Enterprise Data
In the dynamic realm of business technology, integrating LLMs into enterprise data systems heralds a transformative era of interactive and intuitive processes. These cutting-edge AI-driven tools are reshaping how businesses engage with their data, thus opening up unprecedented avenues of efficiency and accessibility.
LLMs have achieved impressive results in various natural language processing (NLP) tasks, such as answering questions, summarization, translation, and dialogue. However, LLMs have limitations and challenges, such as data quality, ethical problems, and scalability. Therefore, many enterprises are interested in implementing a chat with their data implementation using LLMs, which offer several advantages for their business goals.
One of the main advantages of using LLMs for this purpose is that they can provide intelligent and context-aware chatbots that can handle customer queries and concerns with human-like proficiency. LLMs can understand the meaning and intent of the user’s input, generate relevant and coherent responses, and even take action by invoking APIs as needed. This improves customer satisfaction and frees human agents to focus on more complex tasks. Another advantage of using LLMs for chat with data implementation is that they can be customized with enterprise-specific data, which leads to more accurate and relevant AI-generated insights and recommendations.
Finally, using LLMs for chat with data implementation can enable more efficient and effective data analysis. LLMs can generate natural language summaries or explanations of the data analysis results, which can help users understand the key findings and implications. In addition, LLMs can generate interactive charts or graphs highlighting the patterns or trends in the data. These features can enhance the user experience and facilitate data-driven decision-making across the organization.
What About Large Context Windows?
Models from OpenAI—for example, the GPT-4 Turbo with a 128K context window and Google’s Gemini Pro 1.5 with 1.5 million token content windows—have generated much enthusiasm and interest. However, a bigger context window alone is not enough. Training an LLM on your data has the following benefits over just using an LLM with a larger context window:
- More accurate and informative answers—When chatting with your data, the LLM can access much more information than it would with a larger context window alone. This allows the LLM to provide more accurate and informative answers to your questions.
- More personalized answers—The LLM can also learn to personalize its answers based on your data. For example, if you chat with an LLM that has been fine-tuned on your customer data, it can learn to provide more relevant answers to your specific customers and their needs. For example, we can use a retrieval engine to index its customer data and then connect the retrieval engine to an LLM. This would allow the company to chat with its customers in a more personalized and informative way.
- More creative answers—The LLM can also use your data to generate more creative and interesting answers to your questions. For example, if you chat with an LLM that has fine-tuned your product data, the LLM can learn to generate new product ideas or marketing campaigns.
Of course, LLMs with a larger context window have their own benefits, but they can be a double-edged sword with some limitations. Larger context windows allow us to pass in more information in one API call and worry less about chunking up the application. For example, the recently announced GPT-4.5 Turbo has a 128K context window, allowing for approximately 300 pages of text in a single prompt, compared to approximately 75 pages from the earlier GPT-4 32K model.
On the flip side, having a larger context window has its challenges. For example, larger context window LLMs can be more computationally expensive to train and deploy. They can also be more prone to generating hallucinations or incorrect answers, as large context windows increase the complexity and uncertainty of the model’s output. LLMs are trained on large, diverse datasets that may contain incomplete, contradictory, or noisy information. When the model is given a long context window, it must process more information and decide what to generate next, which can lead to errors, inconsistencies, or fabrications in the output, especially if the model relies on heuristics or memorization rather than reasoning or understanding.
In contrast, chatting with your data can be more efficient and less prone to errors, mainly because when chatting with our data, we are grounding on that data and steering the model to use. The LLM can access a wider range of information and learn to personalize its answers based on your data. Ultimately, the best way to choose between a larger context window LLM and chatting with your data will depend on your specific needs and resources.
Benefits of Bringing Your Data Using RAG
Enterprises often struggle to extract meaningful insights from unstructured data sources such as emails, customer feedback, or social media interactions. When enterprises integrate their data using RAG in LLMs, they unlock many advantages, enhancing the functionality and applicability of these AI systems in their unique business contexts.
This feature offers distinct advantages over merely expanding the context window of these models. The pattern enhances the relevance and accuracy of LLM outputs and provides strategic benefits that a larger context window alone cannot match. LLMs can analyze this data, interpret it in a human-like manner, and provide actionable insights, all in a fraction of the time it would take using traditional methods.
Integrating RAG with real-time enterprise data ensures that the information retrieved and included in responses is relevant and current, a critical factor in rapidly evolving industries. This customization leads to more precise and applicable answers, which is especially beneficial for sectors with specialized knowledge, such as legal, medical, or technical fields.
The key advantage of using enterprise-specific data in conjunction with RAG models lies in the tailored accuracy and applicability of the model’s responses. LLMs with a larger context window can process more information in a single instance, but they may still lack the depth of knowledge in specialized domains. When enterprises introduce their data, the LLMs can generate responses intricately aligned with the organization’s specific industry, jargon, and operational intricacies. This specificity is crucial for industries where specialized knowledge is paramount and goes beyond the scope of what a larger context window can provide.
While a larger context window allows for a broader range of preexisting information to be considered in the model’s responses, it does not necessarily incorporate the most current or enterprise-specific data. In addition, the larger the context window, the more the model has to process and the slower it is.
Furthermore, integrating proprietary data enhances decision-making processes more effectively than simply expanding the context window. This integration enables LLMs to offer insights and analysis deeply rooted in the enterprise’s historical data and strategic objectives. In contrast, a larger context window might provide broader information but lacks precision and direct relevance to enterprises’ strategic questions and challenges.
Regarding data security and privacy, bringing proprietary data under enterprise control is more manageable than relying on public or generalized data that a larger context window might access. By controlling data inputs, enterprises can more effectively ensure compliance with data privacy regulations.
Implementing RAG with your data offers significant advantages for AI safety in enterprise environments, primarily by enhancing the accuracy and reliability of information. This fusion of generative capabilities of LLMs with a comprehensive corpus of data allows the model to access up-to-date, factual data, crucial for enterprises dealing with time-sensitive and accuracy-critical information. Moreover, by retrieving from a diverse set of sources, RAG can mitigate biases inherent in the training data of LLMs, a vital feature for making unbiased, data-driven decisions. Enterprises can customize the retrieval corpus, ensuring alignment with industry regulations and internal policies. Furthermore, incorporating the latest information and providing sources for generated content offers improved transparency and decision-making support.
While expanding the context window of LLMs offers certain benefits, integrating proprietary data with RAG models provides specificity, current relevance, strategic alignment, personalization, data security, and innovation potential that a mere increase in the context window cannot match. This approach enables enterprises to use LLMs more effectively for their unique business needs and objectives.
GenAI Architecture Principles
When building mission-critical applications, enterprises focus on creating a robust, scalable, and secure system. Although the traditional architectural principles remain unchanged, key additional architectural aspects for generative AI are outlined in Figure 2.
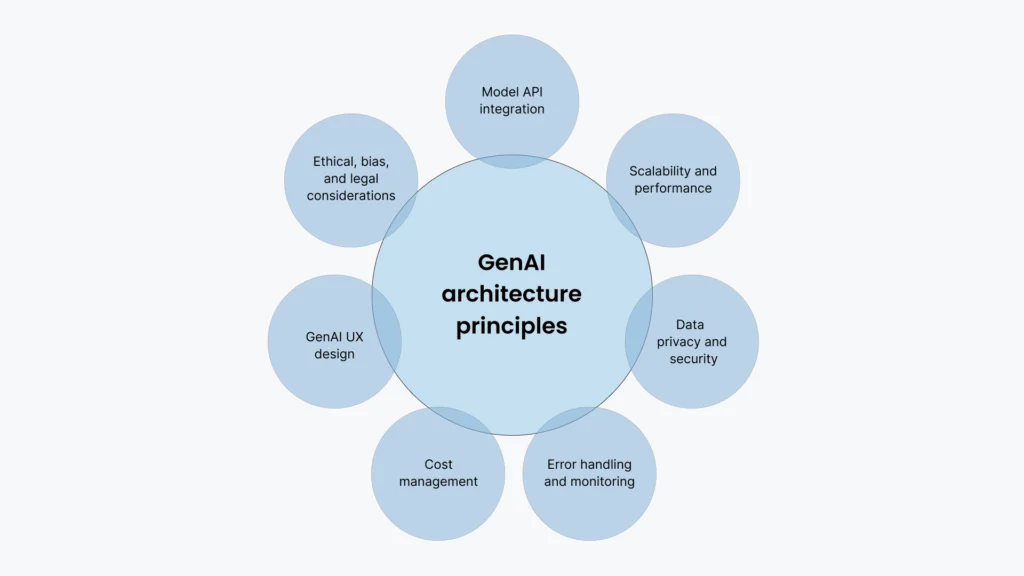
Many GenAI models are accessed via an API, so the model API integration is an architecture principle that helps connect with the GenAI API. The models and APIs have different ways of formatting and sending data, as well as limits and quotas on how many requests they can handle; thus, it can be helpful to create a layer of abstraction that can adjust to changes in each API’s design. This involves handling API requests and responses and managing API limits and quotas. It is also common to have multiple models used in the same application to choose the right model for each situation. Having an abstraction layer can help protect each API’s design from changes.
As a principle, scalability and performance help the application deal with elastic scale and changing loads as they increase and decrease. This involves selecting the appropriate cloud infrastructure, balancing the load, and potentially using asynchronous processing to manage intensive tasks. Moreover, the use of containerization and microservices architecture can help with both scalability and performance.
Hosting LLMs in an enterprise data center is not a trivial task, as it requires careful planning to achieve scalability and performance. You must choose an appropriate LLM architecture, comparing open source and proprietary alternatives that align with the business goals. A streamlined end-to-end pipeline is crucial for smooth operations, using orchestration frameworks for workflow management. The infrastructure should be solid for GPU optimization and simplified infrastructure management. LLMOps should be applied for best practices in deployment, and continuous monitoring for performance tracking should be set up. Scalability should be ensured through load balancing and auto-scaling. The data and models should be secured with encryption and access controls, and industry regulations should be followed. This comprehensive approach ensures that LLMs can serve multiple internal customers efficiently and reliably. Of course, it involves significant and continuous investment in capital expenditure and technical expertise.
Due to the data’s sensitive nature, it is crucial to implement strong data privacy and security measures, which include encrypting data both in transit and at rest, managing access controls, and ensuring compliance with regulations such as GDPR or HIPAA. In addition, it is important to have a data minimization strategy where only necessary data is collected and processed, and security audits and penetration testing should be conducted regularly to identify and address vulnerabilities proactively. Some cloud providers, such as Azure, offer robust enterprise support systems and compliance solutions.
Error handling and monitoring do not constitute a new architecture principle; with distributed systems, if you do not plan for failure, you are planning to fail. Use effective error handling and monitoring to check the GenAI application’s health. This means logging errors, creating alerts for anomalies, and having a plan for handling downtime or API limits, including using automatic recovery strategies, such as fallback mechanisms, to ensure high availability. Distributed tracing is essential for complex, microservice-based architectures to better track problems.
LLMs are evolving cost and currency meanings. LLM usage growth can lead to unexpected expenses. To control costs, optimize API calls and use caching strategies. Have budget alerting and cost forecasting mechanisms to avoid surprises.
The GenAI UX design focuses on how users interact with the GenAI models. This would vary depending on the model type; for a language-based use case using an LLM, the UX design would be quite different from an image-based use case where you would be using Stable Diffusion or DALL-E. This includes designing intuitive interfaces, providing helpful prompts, and ensuring the model’s responses align with user expectations. In some ways, everything should not be a simple chatbot, but it should extend and enhance the experience based on the task and intent.
Consider the ethical, biased, and legal implications of GenAI apps, especially when using LLMs. Mitigate biases and prevent harmful stereotypes. Understand legal consequences in healthcare, finance, or law. Follow relevant laws and industry standards.
Build GenAI Applications the Right Way with Anaconda
From robust API integration to enterprise-grade security, observability, and ethical AI practices, building GenAI applications requires more than just a model—it requires an architecture built for scale, governance, and reliability. The Anaconda AI Platform combines secure infrastructure, powerful tooling, and seamless integration with your existing systems to help your organization move from experimentation to enterprise-grade deployment.
Contact our team today to learn how Anaconda can support your journey to scalable, secure, and responsible generative AI.