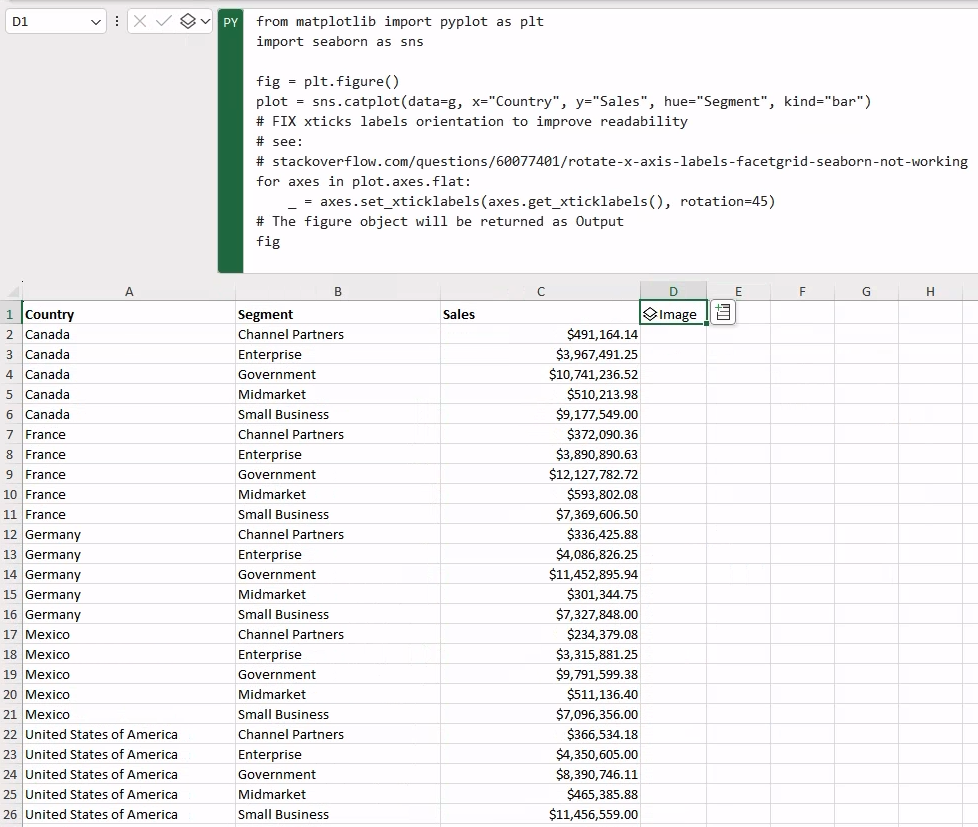
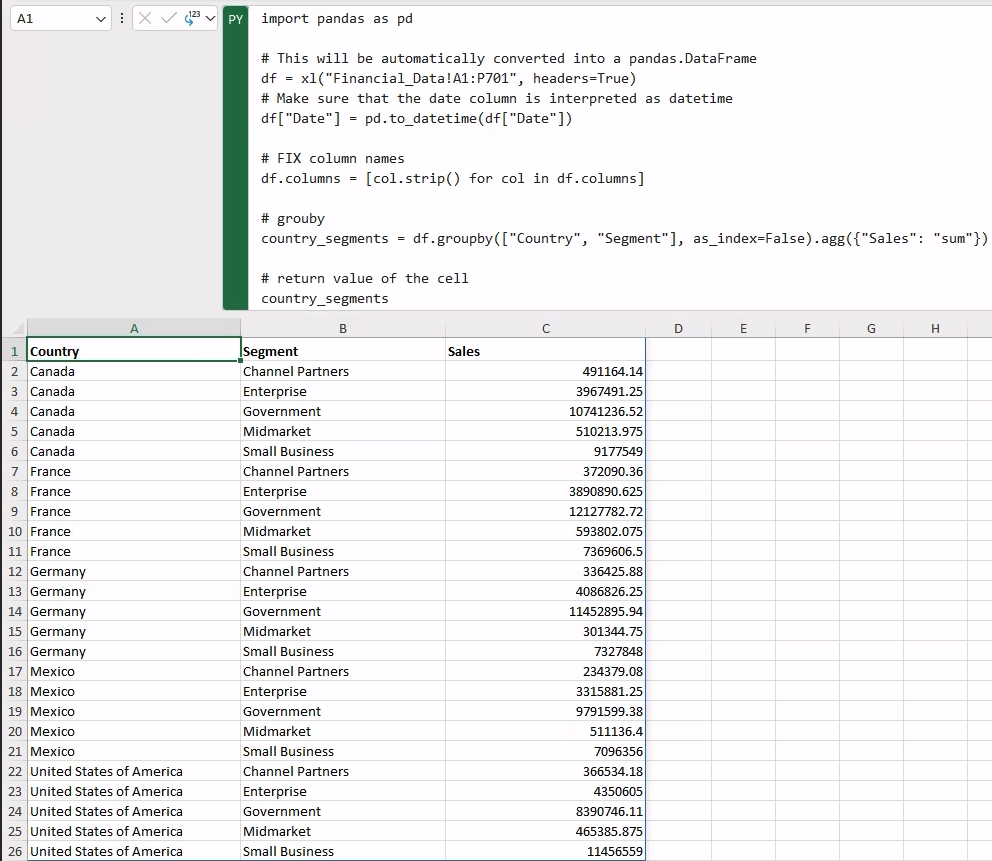
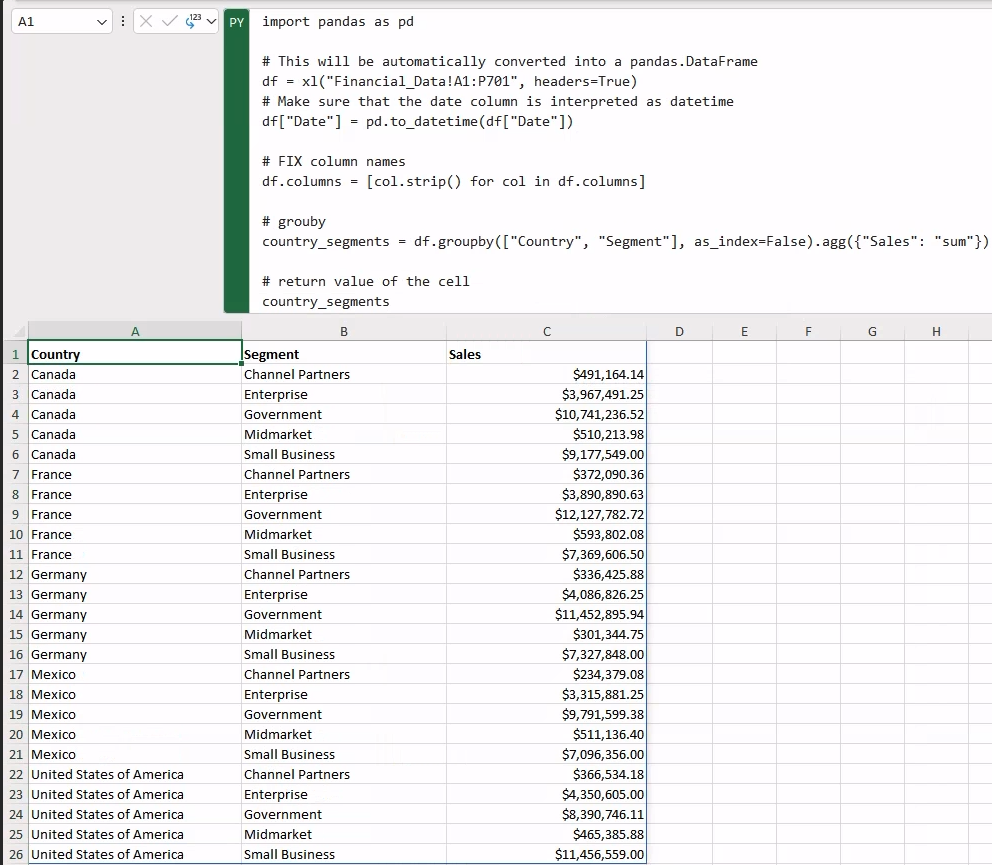
Now that we have our aggregated data, let’s generate a plot of the aggregated sales using Seaborn. Specifically, we will be generating a catplot as our aggregation axes are categorical (namely Country and Segment).
Let’s move onto the cell D1 and type in =PY. However, this time let’s mark its output as a Python object by clicking on the drop-down menu next to the left side of the cell.
The default output of a Python cell is set as “Excel value,” which is marked in the dropdown menu with this icon: ![]() . When we set the output of the cell as “Python object,” the icon in the menu becomes this one instead:
. When we set the output of the cell as “Python object,” the icon in the menu becomes this one instead: ![]() .
.
When it comes to displaying images in cells, the default “Excel value” output will display the image directly within a cell. However, if we decide to detach the image from the cell, all the (Python) code used to generate the image will be lost.
This is generally not an issue, but for the sake of this post we want to keep the Python code in the cell and visualize the resulting plot. So, setting up the output of a cell as a Python object is a more flexible solution.
Let’s now add the following Python code to the newly created Python cell in D1:
Python
from matplotlib import pyplot as plt
import seaborn as sns
fig = plt.figure()
plot = sns.catplot(data=country_segments, x="Country", y="Sales", hue="Segment", kind="bar")
# FIX xticks labels orientation to improve readability
for axes in plot.axes.flat:
_ = axes.set_xticklabels(axes.get_xticklabels(), rotation=45)
# The figure object will be returned as Output
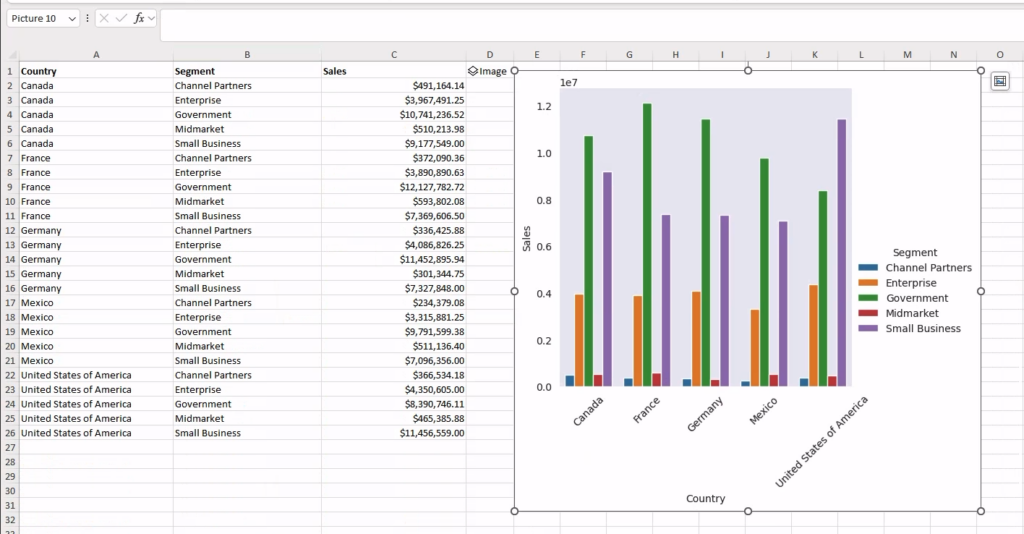
fig When we commit and run the code, this is what you should see in your workbook: