Guest blog written by Thomas Schaeck, Distinguished Engineer | IBM Data & AI
Is it possible to use best of breed open source, and be secure at the same time?
In this blog post we give a brief overview of IBM Cloud Pak for Data and explain how it integrates with Anaconda Repository with IBM in order to meet enterprise requirements for controlled, reliable, and performant use of best of breed data science and machine learning packages by data scientists.
From Data to Predictions to Optimal Actions with IBM Cloud Pak for Data
Cloud Pak for Data covers the Data and AI Life Cycle, providing integrated capabilities to
- connect, transform, virtualize, and catalog data
- explore, visualize, understand, prepare, and if needed label data
- extract features, train, evaluate, and test models
- deploy and monitor models for production use
The above capabilities are provided through Data Virtualization (DV), Watson Knowledge Catalog (WKC), Watson Studio (WS), Watson Machine Learning (WML) and Watson Open Scale (WOS) components included in Cloud Pak for Data, covering the data and AI life cycle as illustrated in the picture below.
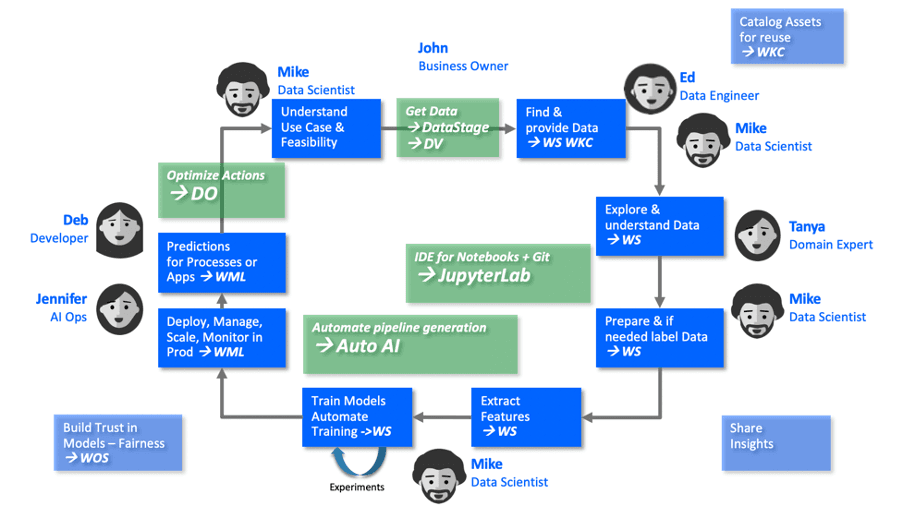
Decision Optimization can be added to determine optimal actions based on predictions, and predictions can be monitored for performance and potential fairness issues to inform corrective action.
For more info on Cloud Pak for Data see our recent blog post.
Collaborate in a secure, scalable, cloud native environment with Cloud Pak for Data
To enable data engineers, data scientists, subject matter experts and other users to collaborate, Cloud Pak for Data provides Projects. In projects users can add members to collaborate with, using a range of tools such as Auto AI, analytic flows, data flows, and very importantly Notebooks and Scripts to run their own Python or R code.
Notebooks and Scripts are powered by Runtime Environments in which JupyterLab allows to create and run Jupyter Notebooks and Scripts. Runtime environment definitions allow to specify the number of virtual cores, gigabytes of memory, and optionally number of GPUs required to run Notebooks and Scripts in an environment. Users can also specify a software configuration with packages to be loaded on environment startup in addition to packages that are pre-loaded for runtime environments.
But how do you secure and control the environment for all developers and data scientists in an enterprise?
Often, enterprises have a need to ensure that their developers and data scientists use only packages that are approved for use in projects in the enterprise. Also, enterprises may have their own proprietary packages that also need to be made available to data scientists. In order to ensure fast start up times for runtime environments and fast, reliable loading of packages from within Notebooks or Scripts, enterprises often need a caching solution to accelerate package loading to be faster than loading packages from remote origins on the Internet.
IBM and Anaconda recently announced a partnership to help enteprises achieve just that
Anaconda Repository with IBM integrated with IBM Cloud Pak for Data solves for these needs. As visualized in the picture below, custom runtime environments can be defined to load packages from conda channels served by Anaconda Repository with IBM, to run Notebooks and Scripts using these packages. Alternatively, code in Notebooks or Scripts can load packages via Conda.
To ensure that developers and data scientists only use approved packages, customers may block access to packages on the internet from the Cloud Pak for Data environment, forcing that all package loading goes through Anaconda Repository with IBM. Anaconda Repository with IBM caches packages originating from the Internet and allows admins to upload a customer’s own proprietary packages to serve up securely and with consistent performance in addition to the cached open source packages.
Configuring Cloud Pak for Data to use Anaconda Repository with IBM is easy
First, an administrator of the system needs to edit an RC file on the Cloud Pak for Data system to add the Anaconda Repository with IBM service as a server of conda channels, from which Cloud Pak for Data will then know to load packages.
Then data scientists and other users working in Cloud Pak for Data projects can create runtime environment definitions and specify which channels and packages they want to use in their Notebooks and Scripts, so that the packages that they use are loaded from conda channels served by Anaconda Repository with IBM.
The following picture shows the software customization of a runtime environment in a project on Cloud Pak for Data, where a channel and package were added.
Now data scientists can simply import the package in Notebooks and Scripts in their project, which will trigger loading the package from the channel served by Anaconda Repository with IBM.
More information