I’m very happy to announce that starting today, we will be publishing summarized download data for all conda packages served in the Anaconda Distribution, as well as the popular conda-forge and bioconda channels. The dataset starts January 1, 2017 (April 2017 for Anaconda Cloud channels) and will be updated roughly once a month. We hope these data will help the community understand how quickly new package versions are being adopted, which platforms are popular for users, and track the usage of different Python versions. For example, this dataset can be used to see how the Python 2 to 3 transition has been progressing for the past 2 years:
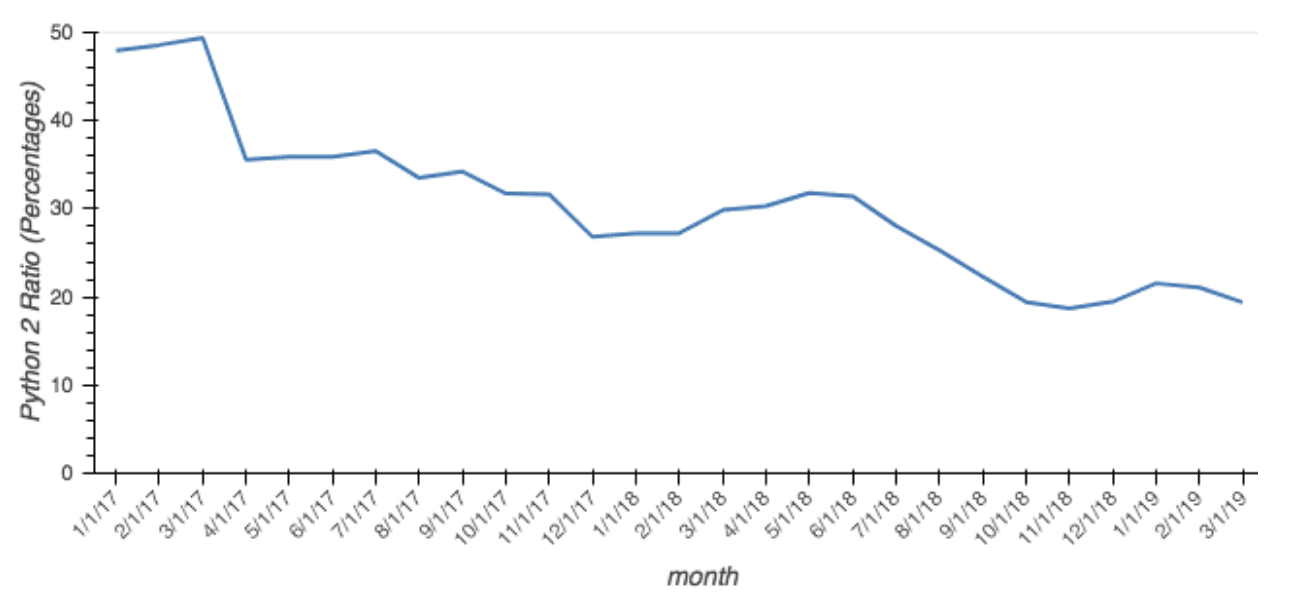
The fraction of packages downloaded for Python 2 (relative to all Python) has dropped from 48% to 19% in the past 26 months. To make it easier to analyze, and to lower bandwidth requirements, the dataset consists of pre-aggregated download counts per hour for all unique combinations of channel, package name, package version, platform, and required Python version (if any). This should allow you to filter and collapse dimensions to quickly find the information you are interested in. The download data is available in the Parquet file format on Amazon S3. To get you started, we have an example notebook that you can run on Binder. Full details on the schema and how to access the data can be found in this Github repository. We are making this data available for free under a CC-BY-4.0 license, without any S3 charges to the end user, to minimize the barriers to analyzing this data. The Intake data catalog we have published along with the data will cache the files locally, which both improves performance and saves bandwidth. All data updates will be announced in the CHANGE_LOG, so please don’t redownload the entire dataset unless that file shows an update. We have ideas for other package datasets we can share in the future that will be of interest to the Anaconda community, so keep an eye on that repo. If you have specific requests or have questions about the data, please open an issue. Happy analyzing!