We’ve witnessed a lot of community grumbling about Conda’s speed, and we’ve experienced it ourselves. Thanks to a contract from NASA via the SBIR program, we’ve been able to dedicate a lot of time recently to optimizing Conda. We’d like to take this opportunity to discuss what we did, and what we think is left to do.
Less is more
The majority of the work centers on reducing the workload that Conda performs. There are three major avenues for this:
- Shrink the number of packages that need to be loaded, processed, and considered in the solution
- Lock down packages that are not involved in the solution, so that the solver’s job is simpler
- Reduce the file size necessary to download packages
For shrinking the package metadata, Conda 4.7 starts out by removing the old “free” channel from the defaults collection. This reduces the package space of the defaults channel by ~40%, and dramatically improves the quality of the metadata.
Next, conda-metachannel pioneered the idea of a reduced repodata.json file that is specific to your particular solve. This is reducing the package space by cutting out packages by name. That’s a great idea, and it works well for the dynamic process behind conda-metachannel. For Conda’s static repodata, we’re not quite there yet, but conda-build now produces a separate file, current_repodata.json. Unlike conda-metachannel, this does not affect the package space by package name. Instead, it is a reduction of the package space by version, which is something of a proxy for time. Conda-build recurses on the initial set of only-latest packages to ensure satisfiability.
For example, many versions of python are present, so that the newest builds of other python software that require the different python versions will work. Conda looks first for this current_repodata.json file, and attempts to find a solution with this subset of the repodata. This either works or fails very quickly. If it fails, Conda falls back to the complete repodata.json and tries again. This fallback is generalized so that Conda can support any number of custom repodata filenames to attempt, and we’ll continue to develop this idea into “epochs” – minimal snapshots of the newest packages at a given point in time. Because this is so early in the process, and because it eliminates old packages that may have problematic metadata, this is a very effective optimization.
Let’s test that with some environment creation. We’ll use conda-forge, because it is a larger channel than defaults. The command we’ll run is:
<span>conda clean -iy rm -rf ~/.conda CONDA_INSTRUMENTATION_ENABLED=1 conda create -n py37env -y -vv -c conda-forge python=3.7</span>
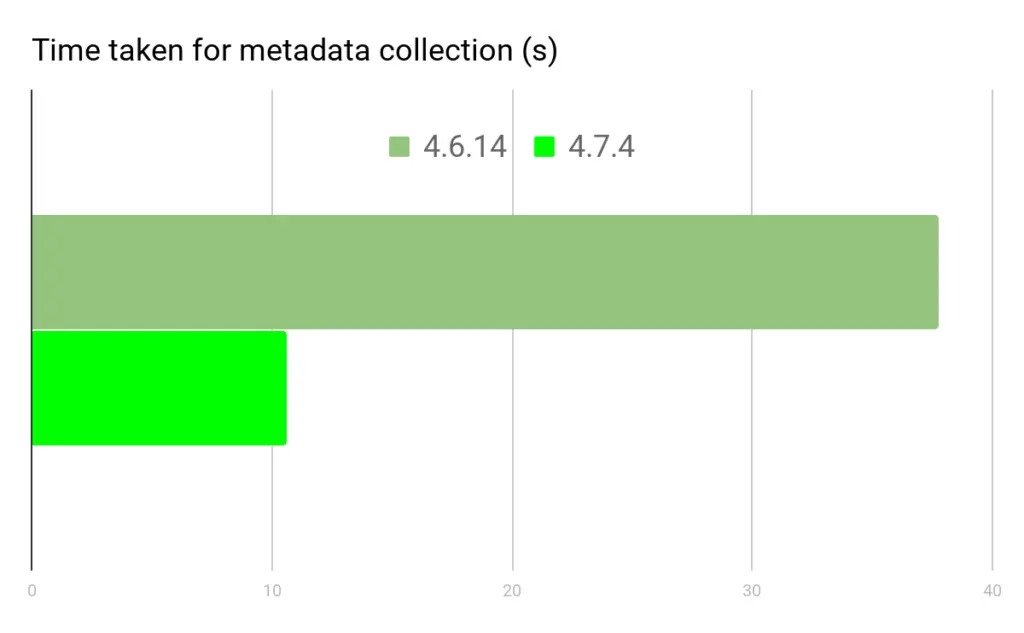
We observe a 3.5x speedup here. This is primarily because of the dramatically reduced size of the repodata being downloaded (and then parsed and loaded) from defaults and conda-forge. You’ll see this benefit as long as your specs are satisfiable using the limited current_repodata.json index. There will be a balance between constraining tightly to speed things up, and pinning loosely to ensure that the smaller index can be useful. In practice, we find that it is less work for the user to not constrain their dependencies much at all, and the new limited index will dramatically benefit those use cases. It is also worth noting that these benchmarks include download and metadata readup that is cached. This speedup should not be interpreted as applying to every Conda operation – only ones where the repodata cache doesn’t yet exist, or where it is too old and needs to be replaced.
For locking down packages, we have expanded an older feature, –freeze-installed. Without this flag, Conda inserted specs for each package that was already installed in your environment with a target set to the exact spec matching your existing package. That target penalized change to the package in the solver, but it didn’t reduce the size of the solving problem. The –freeze-installed flag tweaked that behavior. Rather than specs with targets, the specs representing the present environment were created as exact specs (no target). This is a lot more restricted and more likely to fail.
What we changed was to pre-determine what existing packages conflict with your explicit specs (and thus can’t be frozen), and freeze everything else. That’s now Conda’s default behavior, rather than being behind the –freeze-installed flag. If you take a look at the solver’s problem behind the scenes by using the -vv flag to Conda, you’ll see output that shows the effectiveness of this step at reducing the solving problem size:
<span>conda create -qy -n py37env python=3.7 && conda install -n py37env -y -vv imagesize</span>
| Conda 4.6.14 | Conda 4.7.4 |
| python: pruned from 149 -> 122 pruned from 139 -> 97 setuptools: pruned from 256 -> 180 python: pruned from 122 -> 6 libffi: pruned from 5 -> 4 libgcc-ng: pruned from 8 -> 7 libstdcxx-ng: pruned from 8 -> 7 ncurses: pruned from 8 -> 2 openssl: pruned from 40 -> 10 readline: pruned from 6 -> 3 sqlite: pruned from 17 -> 6 libedit: pruned from 3 -> 2 pruned from 6 -> 3 pruned from 9 -> 1 zlib: pruned from 9 -> 4 pruned from 97 -> 6 setuptools: pruned from 180 -> 12 certifi: pruned from 42 -> 6 wheel: pruned from 51 -> 8 imagesize: pruned from 18 -> 2 gen_clauses returning with clause count: 672 |
python: pruned from 66 -> 1 libffi: pruned from 2 -> 1 libgcc-ng: pruned from 8 -> 1 libstdcxx-ng: pruned from 8 -> 1 ncurses: pruned from 4 -> 1 openssl: pruned from 16 -> 3 readline: pruned from 4 -> 1 sqlite: pruned from 12 -> 1 libedit: pruned from 3 -> 1 tk: pruned from 3 -> 1 zlib: pruned from 3 -> 1 xz: pruned from 4 -> 1 pip: pruned from 34 -> 1 setuptools: pruned from 52 -> 1 certifi: pruned from 30 -> 6 wheel: pruned from 34 -> 1 imagesize: pruned from 11 -> 2 gen_clauses returning with clause count: 160 |
There are a few things to notice here. First, many of the specs are pinned exactly, and thus there is only one choice in Conda 4.7. What about the packages that have more options? Those are either explicit specs, conflicts with the explicit specs, or members of the “aggressive_update_packages” group, which are always unpinned to keep them as up-to-date as possible. The reduced number of options for each package reduces the number of clauses going into the first pass of the solver by a factor of ~5 here. Later passes that consider indirect dependencies are often more dramatically reduced. This optimization will be increasingly beneficial to you as you incrementally build up more complicated environments.
What does that translate to in terms of solve time? To examine this, let’s make the problem a bit harder, and let’s also use Conda’s built-in instrumentation. We’ll create an env with python and numpy, and then add pytorch to it.
<span>conda create -qy -n py37env -c conda-forge python=3.7 numpy CONDA_INSTRUMENTATION_ENABLED=1 conda install -n py37env -y -vv -c conda-forge -c pytorch pytorch</span>
Here in the later stages of the optimization/solving (optimizing indirect dep version/build), we’ve reduced the problem by a factor of ~25. We see 14380 clauses for Conda 4.6.14, and 557 for 4.7.4. Conda’s time spent in the Resolve.get_reduced_index(), Resolve.solve() and Solver._run_sat() are captured in the plot below.
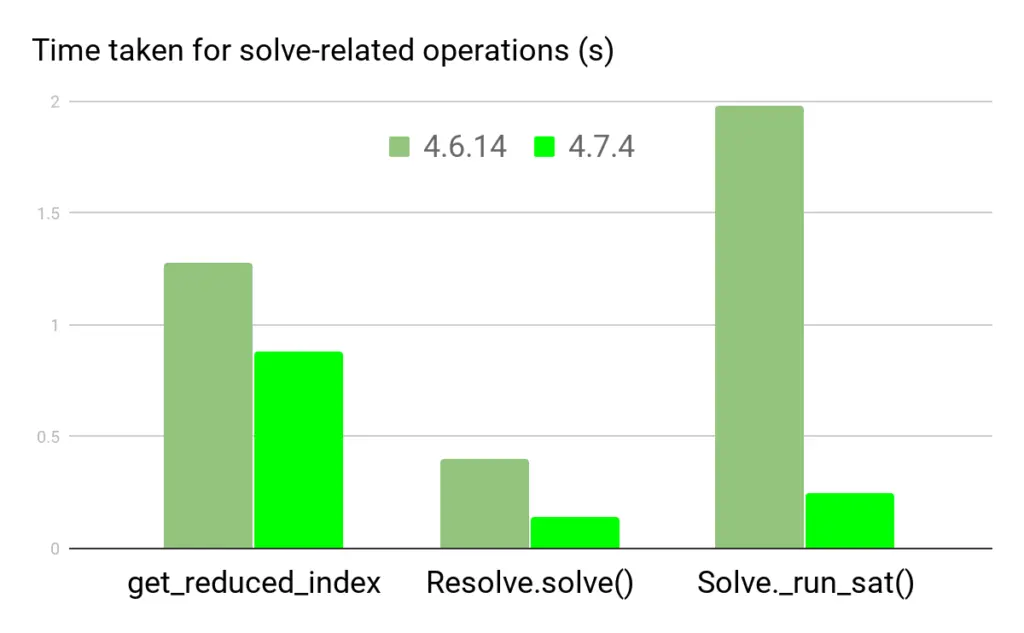
The get_reduced_index method occupies a much larger fraction of the time now. That method is doing more work than it used to, in determining which specs can and can’t be frozen. Fortunately, get_reduced_index is pretty straightforward metadata processing, and we’re confident that we can speed this up dramatically using compiled code. This is an area where we’ll be looking to learn from the Mamba project, which has pioneered C++-based processing of Conda metadata.
As far as download size goes, we’re either playing with stripping binaries, or improving compression. We’ve opted not to strip binaries too much, because when we do that, the debugging info goes out the window making it much harder to help people. We have improved compression with our new file format, the .conda format. We wrote about that in our last blog post, and now it’s finally here. Conda’s download sizes are reduced ~30-40%, and extraction is dramatically faster.
We’re working on rolling out the new file format to all of the channels that we host on our CDN. This takes time because the actual conversion of a .tar.bz2 that is uploaded to the channel may take quite a while to convert to the new format. MKL, for example, can take 30 minutes per package that we need to convert. We use a very high compression setting for zstd, 22, and that takes a while to do its thing. Unfortunately, we won’t be able to offer the new file format to arbitrary anaconda.org channels for the time being, as the application behind anaconda.org does not support the new format. CDN-hosted channels are special, because they mirror content from anaconda.org, but are then free to do more things, like patching repodata or offering the new format.
Doing things in parallel
There are a few embarrassingly parallel steps in Conda. We haven’t really been using your computer to its full capabilities. We’ve improved a bit on that in Conda 4.7. Specifically, Conda now uses multiple threads (not processes) for:
- Downloading and reading repodata from multiple channels
- Verifying transactions
- Executing transactions
We’ll continue to explore areas of Conda that will benefit from this, and we’ll also continue to evaluate when threads or processes are the right level of parallelism.
Overall breakdown of speedups
Let’s take one more holistic look at the speedups. We’ll run one more command that lets us use as many of the new .conda format packages as possible.
<span>conda clean -iy rm -rf ~/.conda conda create -qy -n py37env python=3.7 CONDA_INSTRUMENTATION_ENABLED=1 conda install -n py37env -y -vv -c defaults -c conda-forge pytorch</span>
This speedup represents a simple best-case where the wins of the new file format dominate. Conda 4.6.14 downloads 1.13 GB, while Conda 4.7.4 with the new package format downloads only 737.6 MB. The new freezing behavior will have more of an effect in larger, old environments. The smaller collection of packages will speed up everything. We expect that it will speed up large environments with lots of packages (more specs) more than small environments. Keep in mind that in order to see that speedup, your environment needs to be satisfiable with the newest versions. Using constraints that Conda can’t satisfy with the latest packages will force Conda to use the full repodata.json.
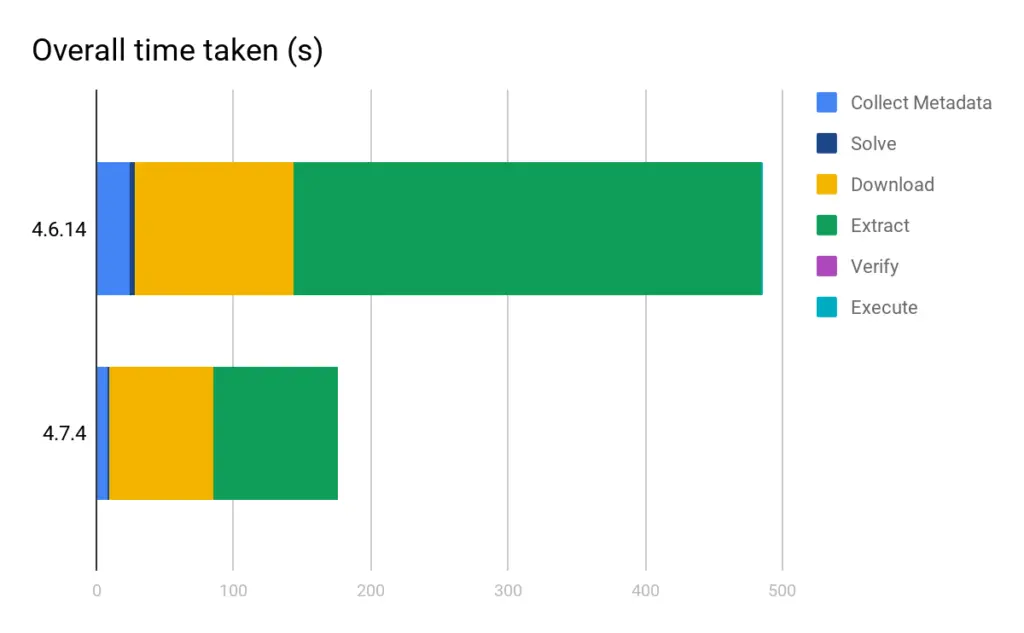
We see approximately a 2.5x overall speedup, almost all thanks to the dramatically faster extraction speed of the zstd compression used in the new file format. This particular example does not stress the solver much, though. We’re hopeful that these optimizations will have a greater effect on the solutions that have been taking several minutes or hours for users, and we’re excited to hear from you how much of a performance improvement you see.
Room for improvement
We’re excited that Conda is faster, but there’s still more work to do. In the coming months, we hope to continue making progress here. Specifically, we’re planning to:
- Parallelize readup of prefix data (existing packages and package cache data)
- Parallelize package downloads and extraction
- Shift repodata handling and spec comparison to compiled code. The new unsatisfiability methods based on get_reduced_index are especially ripe for speedup with compiled code.
- Populate “epochs” of repodata, and make Conda smart about choosing appropriate epochs based on packages present and explicit specs
In addition to these, we were not able to make strict channel priority the default setting for channel priority. We tried, but it was too disruptive. If users had environment files pinned with particular specs that would be unavailable using strict channel priority, that environment file would simply become unusable. We’ll continue to develop on that, because strict channel priority will also interplay with all of the speedups here and give us still a bit more.
Acknowledgments
We are very grateful for the NASA SBIR contract, id NNX17CG19C, which allowed us to focus our attention on this task and make progress faster. Thank you to all of our users and contributors who have both helped us develop these improvements, and otherwise made sure that these improvements don’t mess other stuff up.