Even if you are not a Mac user, you have likely heard Apple is switching from Intel CPUs to their own custom CPUs, which they refer to collectively as “Apple Silicon.” The last time Apple changed its computer architecture this dramatically was 15 years ago when they switched from PowerPC to Intel CPUs. As a result, much has been written in the technology press about what the transition means for Mac users, but seldom from a Python data scientist’s perspective. In this post, I’ll break down what Apple Silicon means for Python users today, especially those doing scientific computing and data science: what works, what doesn’t, and where this might be going.
What’s changing about Macs?
In short, Apple is transitioning their entire laptop and desktop computer lineup from using Intel CPUs to using CPUs of Apple’s own design. Apple has been a CPU designer for nearly a decade (since releasing the iPhone 5 in 2012), but until the end of 2020, their CPUs were only used in mobile devices like the iPhone and iPad. After so many iterations, it became clear to technology observers that Apple’s CPUs, especially in the iPad Pro, had become performance-competitive with low-power Intel laptop CPUs. So it was not a complete surprise when Apple announced at their developer conference in 2020 that they would be moving the entire Mac product line to their own CPUs over the next two years. As promised, Apple released the first Silicon Macs in November 2020. They consisted of a MacBook Air, a 13” MacBook Pro, and a Mac Mini that looked identical to the previous model but contained an Apple M1 CPU instead of an Intel CPU. In April 2021, they added the M1 to the iMac and iPad Pro.
So what’s better about these Apple CPUs? Based on many professional reviews (as well as our testing here at Anaconda), the primary benefits of the M1 are excellent single-thread performance and improved battery life for laptops. It is important to note that benchmarking is a tricky subject, and there are different perspectives on exactly how fast the M1 is. On the one hand, what could be more objective than measuring performance quantitatively? On the other hand, benchmarking is also subjective, as the reviewer has to decide what workloads to test and what baseline hardware and software configuration to compare to. Nevertheless, we’re pretty confident the M1 is usually faster for a “typical user” (not necessarily a “data science user”) workload than the previous Intel Macs while simultaneously using less power.
From a CPU architecture perspective, the M1 has four significant differences from the previous Intel CPUs:
The CPU architecture changes from x86 to ARM
Apple now designs the on-chip GPU (rather than an on-chip GPU from Intel or separate GPU chips from NVIDIA or AMD)
Custom Apple accelerators from the iPhone and iPad chips are now available on the Mac, such as the Apple Neural Engine (ANE)
System RAM is soldered directly to the CPU package and shared by the CPU, GPU, and ANE cores.
We’ll touch on the impact of these changes more in later sections.
Instruction sets, ARM, and x86 compatibility
As software users and creators, our first question about Apple Silicon is: Do I need to change anything for my software to continue working? The answer is: Yes, but less than you might think.
To elaborate on that, we need to dive into instruction set architectures (ISAs). An ISA is a specification for how a family of chips work at a low level, including the instruction set that machine code must use. Applications and libraries are compiled for a specific ISA (and operating system) and will not directly run on a CPU with a different ISA unless recompiled. This is why Anaconda has different installers and package files for every platform we support.
Intel CPUs support the x86-64 ISA (sometimes also called AMD64 because AMD originally proposed this 64-bit extension to x86 back in 1999). The new Apple Silicon CPUs use an ISA designed by ARM called AArch64, just like the iPhone and iPad CPUs they descend from. For this reason, these new Macs are often called “ARM Macs” in contrast to “Intel Macs,” although ARM only defined the ISA used by the Apple M1 but did not design the CPU. In general, the naming conventions for 64-bit ARM architectures are confusing, as different people will use subtly different terms for the same thing. You may see some people call these “ARM64” CPUs (which is what Apple does in their developer tools), or slightly incorrectly as “ARMv8” (which is a specification that describes both AArch64 and AArch32). Even in conda, you’ll see the platform names osx-arm64, which you would use for macOS running on the M1, and linux-aarch64, which you would use for Linux running on a 64-bit ARM CPU. We’ll use “ARM64” for the rest of this post because it is shorter than “Apple Silicon” and less clunky than “AArch64.”
The observant reader will note that ISA compatibility only matters for compiled code, which must be translated to machine code to run. Python is an interpreted language, so software written in pure Python doesn’t need to change between Intel and ARM Macs. However, the Python interpreter itself is a compiled program, and many Python data science libraries (like NumPy, pandas, Tensorflow, PyTorch, etc.) contain compiled code as well. Those packages all need to be recompiled on macOS for ARM64 CPUs to run natively on the new M1-based Macs.
However, Apple has a solution for that, too. Recycling the “Rosetta” name from their PowerPC emulator, Apple includes a system component in macOS 11 called Rosetta2. Rosetta2 allows x86-64 applications and libraries to run on ARM64 Macs unchanged. One interesting fact about Rosetta2 is that it is an x86-64 to ARM64 translator, not an emulator. When you run an x86-64 program (or load a compiled library) for the first time, Rosetta2 analyzes the machine code and creates equivalent ARM64 machine code. This makes a slight upfront delay when you first start an x86-64 application, but the translated machine code is also cached to disk, so subsequent runs should start more quickly. This is in contrast to an emulator (like QEMU) which simulates the behavior and state of a CPU in software, instruction by instruction. Emulation is generally much slower than running a translated binary, but it can be difficult to translate from one ISA to another and have code still run correctly and efficiently, especially when dealing with multithreading and memory consistency.
Apple has not disclosed exactly how they were able to generate ARM64 machine code from x86-64 binaries with good performance, but there are theories they designed the M1 with additional hardware capabilities to enable it to imitate some of the behaviors of x86-64 chips when running translated code. The net result is most people see a 20-30% performance penalty when running x86-64 programs with Rosetta2 compared to native ARM64. That is a pretty reasonable tradeoff for compatibility until the selection of ARM64-compiled software catches up.
However, there is a catch, especially for users of numerical computing packages in Python. The x86-64 ISA is not a frozen specification, but one Intel has evolved substantially over time, adding new specialized instructions for different workloads. In particular, for the last 10 years, Intel and AMD have rolled out support for “vector instructions,” which operate on multiple pieces of data simultaneously. Specifically, these additions to the x86-64 instruction set are AVX, AVX2, and AVX-512 (which itself has different variants). As you might imagine, these instructions can be handy when working with array data, and several libraries have adopted them when compiling binaries for x86-64. The problem is that Rosetta2 does not support any of the AVX family of instructions and will produce an illegal instruction error if your binary tries to use them. Because of the existence of different Intel CPUs with different AVX capabilities, many programs can already dynamically select between AVX, AVX2, AVX-512, and non-AVX code paths, detecting the CPU capabilities at runtime. These programs will work just fine under Rosetta2 because the CPU capabilities reported to processes running under Rosetta2 do not include AVX. However, suppose an application or library does not have the capability to pick non-AVX code paths at runtime. In that case, it will not work under Rosetta2 if the packager assumed the CPU would have AVX support when they compiled the library. TensorFlow wheels, for example, do not work under Rosetta2 on the M1. Additionally, even if a program works under Rosetta2, not having something like AVX makes the M1 slower at doing certain kinds of array processing. (Again, compared to programs that use AVX on Intel CPUs. For various reasons, only some Python libraries use AVX, so you may or may not notice a big difference depending on your use case.)
Getting Python packages for the M1
There are currently three options for running Python on the M1:
Use pyenv to create environments and pip to install native macOS ARM64 wheels or build packages from source.
Use an x86-64 Python distribution, like Anaconda or conda-forge, with Rosetta2.
Use the experimental conda-forge macOS ARM64 distribution.
The first option is currently challenging because very few Python projects have uploaded native ARM64 wheels for macOS. Many Python projects use free continuous integration services (like Azure Pipelines or Github Actions) to build binary wheels, and these services do not yet have M1 Macs available. If you try to pip install a package without a wheel, pip will attempt to build the package from scratch, which may or may not work depending on whether you have the appropriate compilers and other external dependencies available.
The second option offers the broadest range of packages, though not the fastest option. You can download the macOS x86-64 installer for Anaconda (or conda-forge) and install it on an M1 Mac, and everything will work. You will see a warning from the installer that the “architecture does not appear to be 64-bit,” but you can safely ignore that warning. When running Python applications, you may notice a pause (sometimes long!) when starting Python or importing a package for the first time, as Rosetta2 translates machine code from x86-64 to ARM64. However, that pause will disappear on subsequent runs. The main limitation is that packages that require AVX will not run. For example, the TensorFlow 2.4 wheel installed by pip will fail (due to how it is built), however, the TensorFlow 2.4 package from conda-forge will work. You can install it into your conda environment with the command:
conda install conda-forge::tensorflowThe third option is to use the experimental conda-forge distribution built for macOS ARM64. The conda-forge team uses a technique called “cross-compilation” to build macOS ARM64 binaries with their existing macOS x86-64 continuous integration infrastructure. It is an excellent workaround for not having access to M1 Mac hardware but has the drawback that the build system cannot test the packages since there is no M1 CPU to run on. Nevertheless, the packages we’ve tested seem to work fine. If you would like to try out Miniforge for osx-arm64:
Go to the Miniforge download page and download the OSX ARM64 installer.
Follow the installation instructions
Many popular OSX ARM64 packages are available from conda-forge, including PyTorch, TensorFlow (only for Python 3.8 at the moment), Scikit-learn, and pandas.
We are in the process of adding macOS ARM64 as an Anaconda-supported platform. These packages will be built and tested on M1 Macs. These aren’t available yet, but stay tuned!
How are the M1 “efficiency” cores used by Python?
Although sometimes called an 8 core CPU, the M1 is best described as a 4+4 core CPU. There are 4 “high-performance cores” (sometimes called “P cores” in Apple documentation) and 4 “high-efficiency cores” (sometimes called “E cores”). The P cores provide the bulk of the processing throughput of the CPU and consume most of the power. The E cores are a different design than the P cores, trading maximum performance for lower power consumption. While it is unusual for desktop and laptop chips to have two different cores, this is common in mobile CPUs. Background processes and low priority compute tasks can execute on the E cores, conserving power and extending battery life. Apple provides APIs for setting the “quality of service” for threads and tasks, which influences whether they are assigned to P or E cores by the operating system.
However, Python doesn’t use any of these special APIs, so what happens when using multiple threads or processes in your application? Python reports the CPU core count as 8, so if you launch 8 worker processes, half of them will be running on the slower E cores. If you run fewer than 8, the OS seems to prefer running them on the P cores. To help quantify this, we created a simple microbenchmark where we made a function that computed cosine a lot:
import math
def waste_time(_):
n = 1000000
for i in range(n):
math.cos(0.25)And then ran many copies of it in a multiprocessing.Pool with different numbers of processes, computing the throughput. The result is shown in this plot:
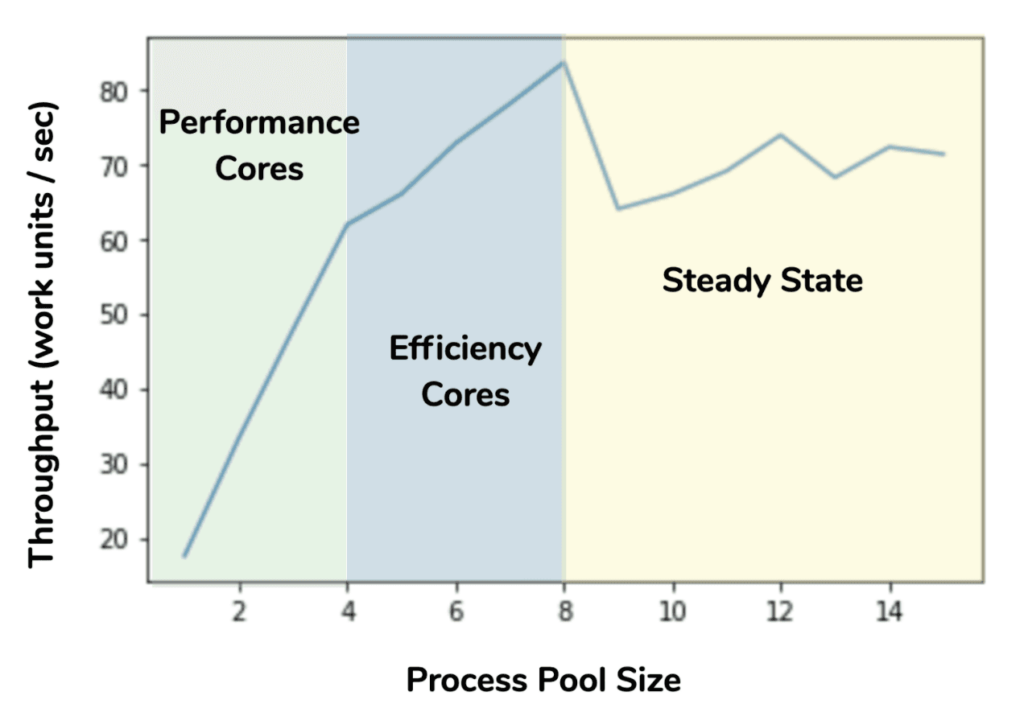
The behavior is consistent with the OS scheduler assigning worker processes to the performance cores when there were four or fewer processes. As the process pool grew past four, the increase in throughput per core was reduced until we hit eight processes, indicating the slower E cores were used for the extra processes. Finally, there are no additional CPU resources to take advantage of the past eight processes, and now scheduling effects and memory contention result in a varied but non-improving throughput. Also, interesting to note that for the peak total throughput of the M1 (in this test), 75% of the throughput is provided by the P cores and 25% is provided by the E cores. That’s a non-trivial contribution from the E cores, so it is a good idea to use them if you can, and your work distribution system can handle tasks that might take very different amounts of time between workers. (That is to say, work must be scheduled dynamically, or work-stealing must be supported.) Running a similar scaling test on an Intel Mac shows that the performance gain from the E cores on the M1 is roughly comparable to the gain from hyperthreading on the Intel CPU. However, the two features are entirely different.
What about Linux and Windows on the M1?
Although Apple has said they will not prevent users from running other operating systems on M1 hardware, there is currently no Boot Camp equivalent for dual-booting an M1 Mac to Linux or Windows, and efforts to port Linux to run natively on M1 hardware are still highly experimental. However, there are (as of this writing) two ways to run Linux on the M1:
In both cases, you need to run a Linux distribution compiled for ARM64, but those are readily available as Linux has been used on ARM systems for a long time. We have found Docker on the M1 to be remarkably straightforward, and the M1 Mac mini is an excellent option for continuous integration systems that need to test Linux ARM64 software, rather than using low-power single-board computers like the Raspberry Pi and the NVIDIA Jetson. For example, Numba’s extensive unit test suite runs about 7x faster in Docker on our M1 Mac mini than a Raspberry Pi 4 running Ubuntu Linux. (Note that we have not yet found a way to run 32-bit ARM Linux distributions on the M1.)
Parallels Desktop can now also run the ARM64 port of Windows, but Windows software for ARM is not as prevalent as Linux software. Windows itself is only available for ARM via the Windows Insider Program, and nearly all software a data scientist is likely to use is available for Linux anyway.
What are the pros and cons for data scientists?
The biggest benefits to the M1 for a data scientist are basically the same as for typical users:
High single thread performance
Excellent battery life (for the laptops)
The M1 Macs do not offer anything that specifically benefits data scientists, but that may be coming (see the next section).
However, M1 is currently aimed at the lowest-power devices in the Apple lineup, giving it several drawbacks:
Only four high-performance CPU cores: Many data science libraries (like TensorFlow, PyTorch, and Dask) benefit from more CPU cores, so only having four is a drawback.
Maximum of 16 GB of RAM: More memory is always helpful for working with larger datasets, and 16 GB might not be enough for some use cases.
Minimal support for the GPU and ANE in the Python data science ecosystem: The tight integration between all the different compute units and the memory system on the M1 is potentially very beneficial. Still, at this point, the only non-alpha Python library that can use the M1 GPU or ANE is coremltools, which only accelerates model inference.
ARM64 package availability: It will take time for the PyData ecosystem to catch up and consistently ship Python wheels for ARM64 Macs, and there will likely be gaps. Running under Rosetta2 might be the better option, as long as you can avoid packages that require AVX and won’t run at all.
Compared to existing Intel Macs, the CPU core count and RAM limitations are significant, although the M1 is very efficient with the resources it has.
What’s on the horizon?
Many of the current drawbacks to the M1 are simply due to it being the first CPU in the new lineup of ARM64-based Macs. To convert the higher performance Macs (especially the Mac Pro) over to this new architecture, Apple will need to release systems with more CPU cores and more memory. At the same time, the Python developer ecosystem will catch up, and more native ARM64 wheels and conda packages will become available.
But the most exciting development will be when machine learning libraries can start to take advantage of the new GPU and Apple Neural Engine cores on Apple Silicon. Apple offers APIs like Metal and ML Compute which could accelerate machine learning tasks, but they are not widely used in the Python ecosystem. Apple has an alpha port of TensorFlow that uses ML Compute, and maybe other projects will be able to take advantage of Apple hardware acceleration in the coming years.
Going beyond Apple, the M1 demonstrates what a desktop-class ARM processor can do, so hopefully, we will see competition from other ARM CPU makers in this market. For example, an M1-class ARM CPU from another manufacturer running Linux with an NVIDIA GPU could also be an impressive mobile data science workstation.
Conclusion
The M1 Macs are an exciting opportunity to see what laptop/desktop-class ARM64 CPUs can achieve. For general usage, the performance is excellent, but these systems are not aimed at the data science and scientific computing user yet. If you want an M1 for other reasons, and intend to do some light data science, they are perfectly adequate. For more intense usage, you’ll want to stick with Intel Macs for now, but keep an eye on both software development as compatibility improves and future ARM64 Mac hardware, which likely will remove some of the constraints we see today.