Anaconda Desktop is currently available through a limited early access program. Anaconda AI Navigator provides many of the same capabilities and is available to all users.
Understanding the API server
The API server is the core component of Anaconda Desktop that enables you to interact with your locally downloaded LLMs through API calls. Access the API server by selecting Model Servers from the left-hand navigation.Server address
Your local server address, often referred to aslocalhost or 127.0.0.1, is the default address for the API server. It is a loopback address, meaning any network communication sent to this address remains within the same machine, keeping your data secure and private. This is common for developing applications.
If you are working in an office network and would like to make your server accessible to other devices within the same network, you can set the server address to your machine’s local IP address. These are typically private networks, meaning they’re not routable on the public internet.
Setting the server address to 0.0.0.0 configures it to accept connections on all network interfaces. This can expose your server to the public internet if your network is configured to allow external connections and route traffic from external sources to your server.
Server port
The server port tells the built-in API server where to listen for incoming traffic (that is, where to listen and pick up API requests). For more information, see Cloudflare’s article on ports.API key
Establish an API key that must be passed as anAuthorization: Bearer token in the header of requests made to your server. You can choose any unique string you want as the API key, but the value you enter on the Model Servers page must match what you use in the Authorization: Bearer header.
Testing your API key
Testing your API key
To test an API key:
- Select Model Servers from the left-hand navigation.
- Enter your API key in the API Key field.
-
Load a model into the API server.
You must use a
text-generationtype model. -
Open Anaconda Prompt (Terminal on macOS/Linux) and run the following command:
Replace <API_KEY> with the value you entered on the Model Servers page.
/completion endpoint to interact with the model you have loaded. If you receive a response, your API key is working. If you receive a 401 error, double check your command and try again.Loading a model
Use the Model dropdown to select the model you want to load into the API server and the File dropdown to choose the quantization level to interact with.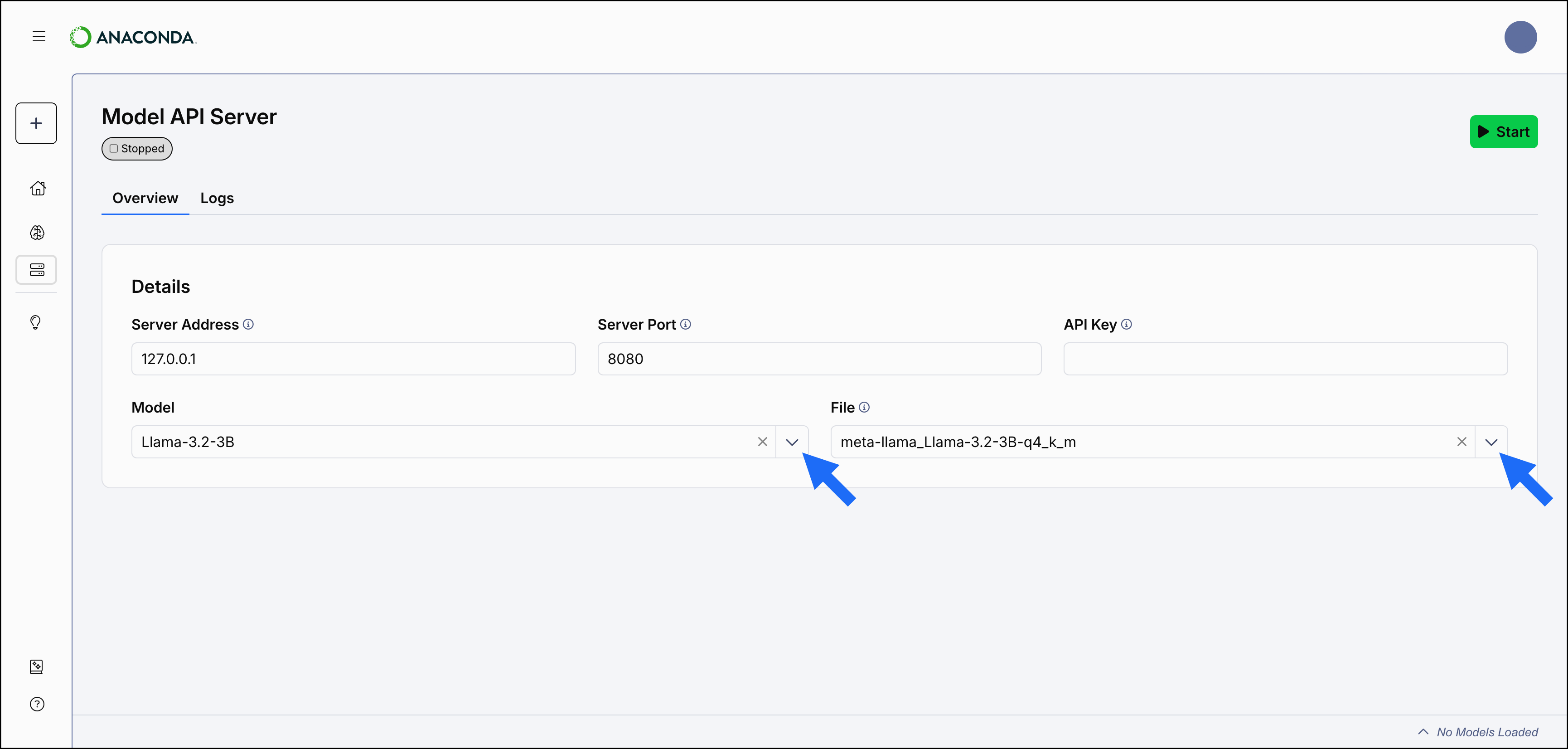
Model won’t load (exit code 3221225781)
Cause
The model you are trying to load requires a C++ runtime environment, but Microsoft does not include one in their operating systems by default.
Solution
Install the Latest Microsoft Visual C++ Redistributable Version.
Starting the server
To start the API server, select Start.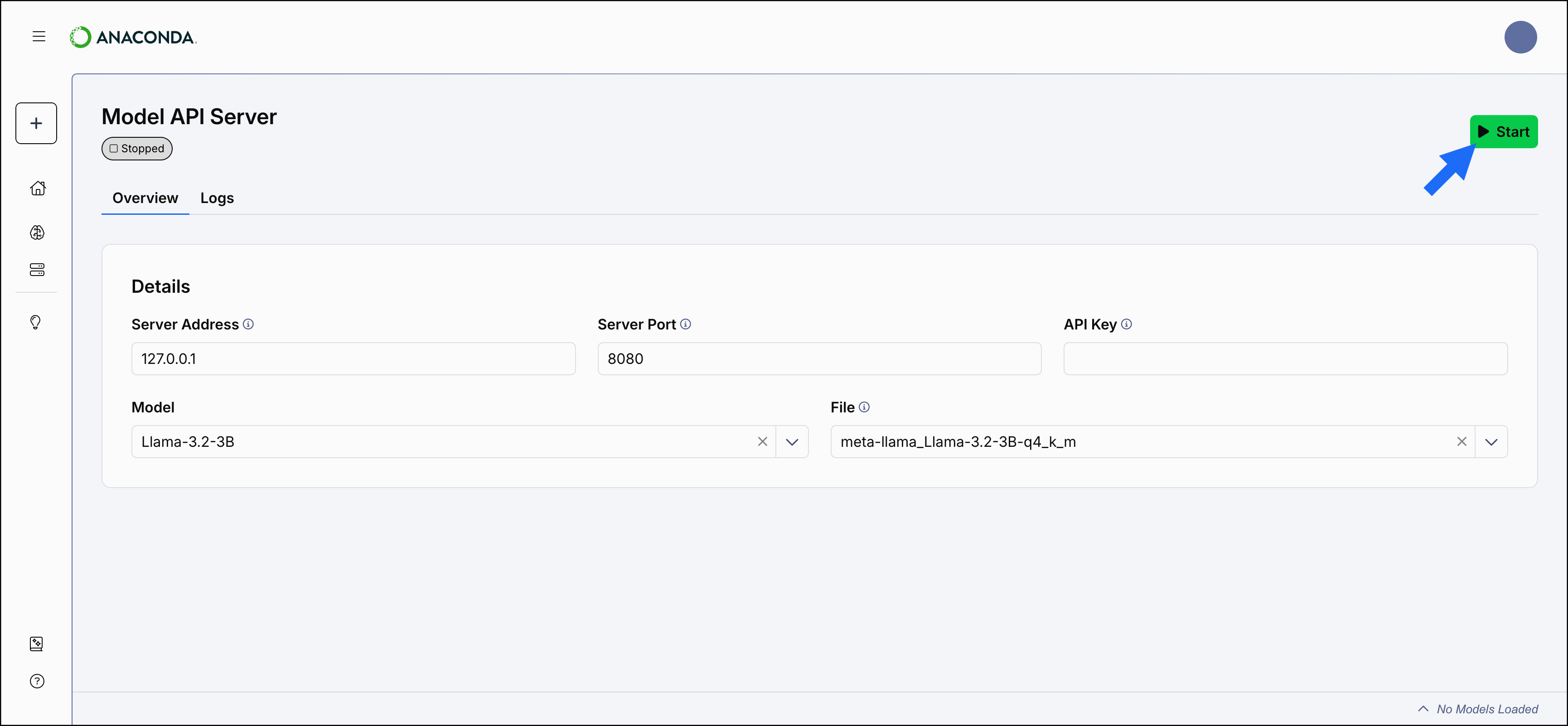
Viewing API server logs
The API server records all incoming traffic for the currently running server and displays relevant information in the Server Logs. To view your server logs, select Logs on the Model Servers page. The server logs provide information for the following metrics:- System information: Provides information about your system’s hardware capabilities.
- Build information: Provides information about the version of the API server you are using.
- Chat template: Shows the sequence of messaging defined for the system.
- Server listening: Displays the server address and port number being listened to.
- Slot information: Displays the number of available slots for the server. Each slot is able to manage one user API request at a time.
- Task information: Displays information such as time spent processing and responding to a request, the request task ID, and which slot fulfilled the task.
<YYYY><MM><DD><HH><MM><SS>_api-server.log), so you can efficiently locate specific server logs if necessary:
- Windows
- macOS
For Windows machines, you can find the logs here:
C:\Users\<USERNAME>\AppData\Roaming\anaconda-desktop\logsConnecting applications to servers
Connecting your application to a model server requires setting two environment variables: thebase_url, which directs your API calls to the server hosting your model, and the api_key, which authenticates your requests.
Follow the steps below to find these variables’ values and save them as environment variables in your application.
Configure your server
From the Model Servers page:
- Note your Server Address and Server Port (the default is
http://localhost:8080). This will be yourbase_url. - (Optional) Set an API Key. You can use any unique string value. If you don’t set an API key, you don’t need to provide an
api_keyin your application. - Load a model and select Start.
Configure your application
Set your credentials as environment variables:
Replace <BASE_URL> with the server address and port you copied from the Model Servers page.
Replace <API_KEY> with the API key you created on the Model Servers page.
Replace <API_KEY> with the API key you created on the Model Servers page.
Setting environment variables is considered a best practice for security. However, for local testing and development, you can add the credentials directly in your code instead.
Environment variables set directly in the terminal will only last as long as the terminal session is active. To make these environment variables permanent, follow your system’s standard process for persisting environment variables.
Environment variables set directly in the terminal will only last as long as the terminal session is active. To make these environment variables permanent, follow your system’s standard process for persisting environment variables.
OpenAI API compatibility
Anaconda Platform model servers are OpenAI API compatible for chat completions. See OpenAI’s Chat Completion API documentation for more information on making chat completion requests.Make sure the model server is running before making API requests.
The
The
model parameter is required but can be left as an empty string since the model is already loaded on the server.If you did not set an API key, change
api_key=os.environ.get('ANACONDA_API_KEY') to api_key="".