Anaconda Desktop is currently available through a limited early access program. Anaconda AI Navigator provides many of the same capabilities and is available to all users.
Loading a model
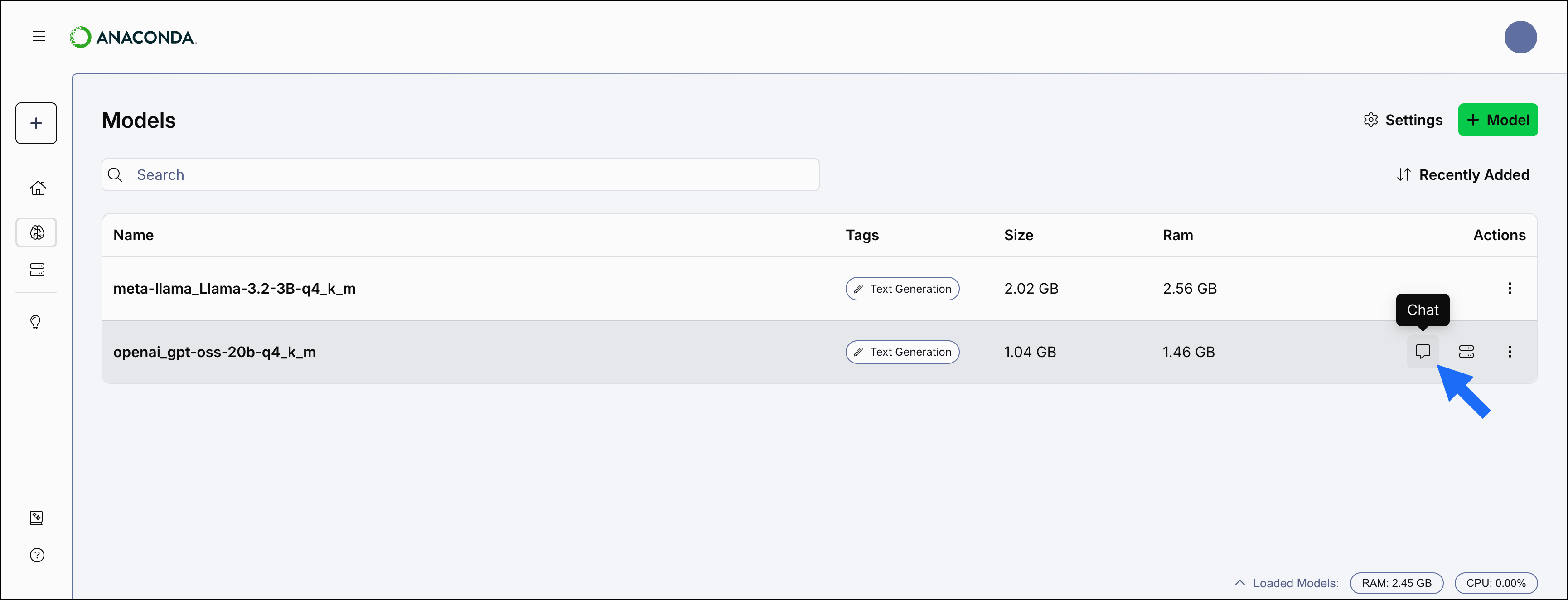
Load a model you’ve downloaded into the chat interface to interact with it. To load a model:- Navigate to the AI Models page.
-
Hover over the model you’d like to chat with and select Chat.
Changing a model
To load a different model to interact with, select the new model from the Model dropdown on the Model Chat page.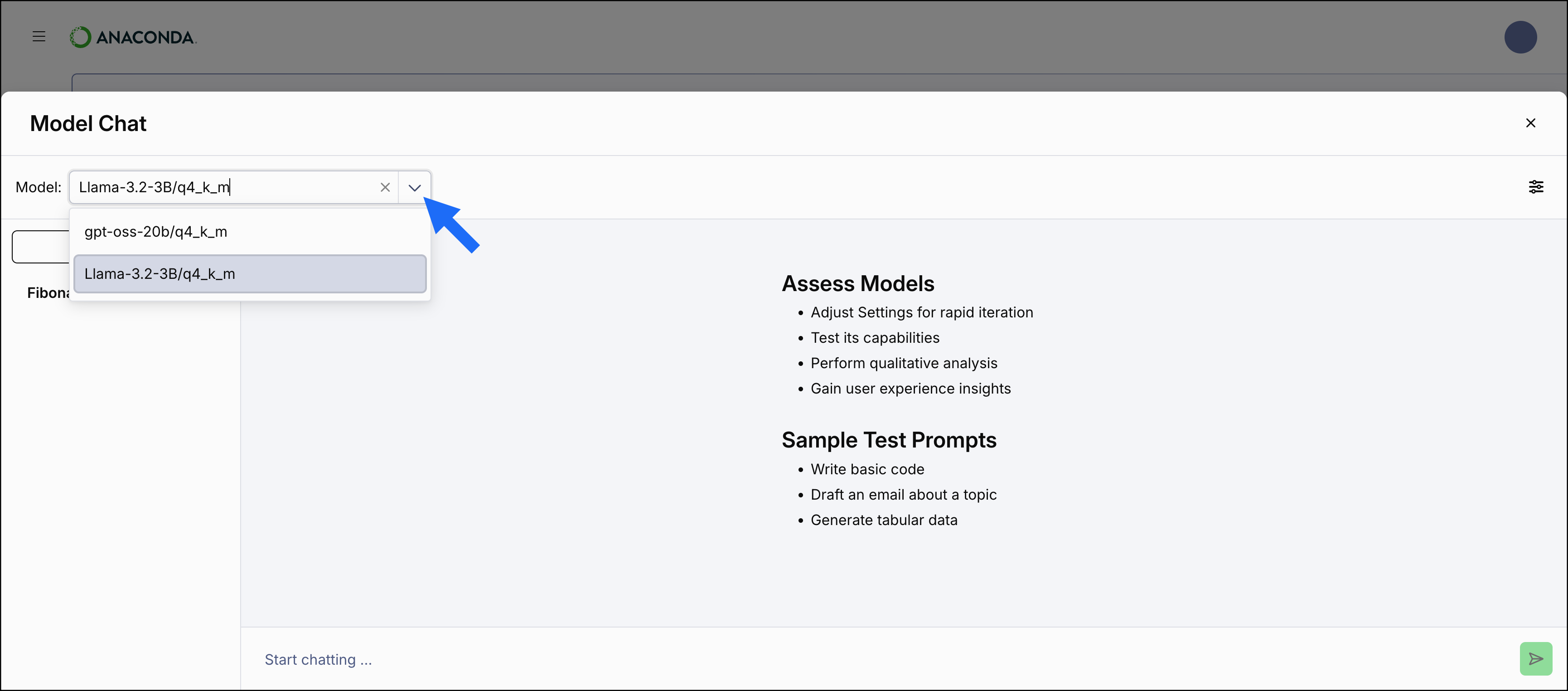
Starting a new chat
All chats are initially created as New Chat<#>, but are topically renamed based on your initial prompt to the model.
To start a new chat:
- From the Model Chat page, select Chat.
- If necessary, load a model into the chat interface.
- Enter a prompt to chat with the model.
Stopping a response
Sometimes a model can start generating a lengthy and off-topic response to a prompt. To stop the model from generating its response, select Stop in the prompt field.Editing a prompt
You can edit your most recent prompt to change the model’s response:- From the Model Chat page, select the actions dropdown in your most recent prompt.
- Select Edit.
- Edit the prompt, then press Enter (Windows)/Return (Mac).
Regenerating a prompt
To ask the model to generate a new response to your most recent prompt:- From the Model Chat page, select the actions dropdown in your most recent prompt.
- Select Regenerate.
Renaming a chat
You can provide a specific name to a chat at any time. To rename a chat:- From the Model Chat page, open a chat’s actions dropdown and select Rename.
-
Enter a name for your chat.
Chat names over 21 characters are truncated.
Deleting a chat
To delete a chat:- From the Model Chat page, open a chat’s actions dropdown and select Delete.
- Select Delete Chat.
Chat settings
Chat settings allow you to fine tune how the model responds during user interactions. Once you have loaded a model, select Settings to open the chat settings.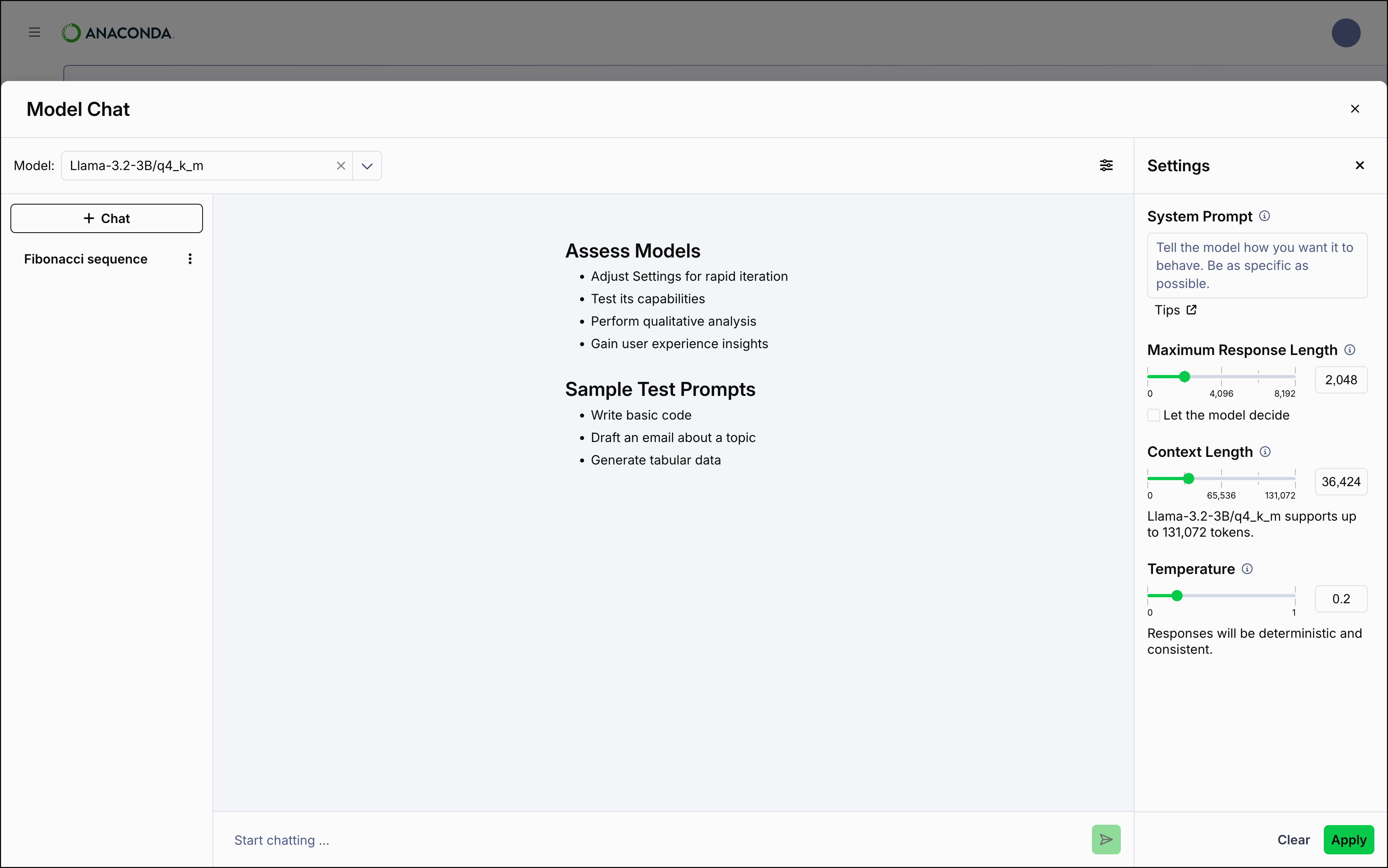
- System Prompt
- Sets the overall tone and behavior for the model before any user input is provided as a prompt. The system prompt is a hidden instruction that establishes the model’s persona. For example, you could instruct the model to act as a data analyst, a python developer, or to adhere to a formal tone. For more information, see Crafting effective system prompts.
- Maximum Response Length
- Adjusts how long the model’s responses can be. Short responses are best suited for succinct answers or summaries of information, while longer responses are better for detailed guidance.
- Context Length
- Defines how much of the ongoing conversation the model can recall. A higher context length allows the model to keep track of more conversation history, which is beneficial for extended discussions. However, this can increase RAM usage and slow down inference, as the model processes more and more history. A lower context length can provide faster responses and reduce memory usage by considering less history.
- Temperature
- Controls the level of randomness in the model’s responses. This can help the model to feel more or less creative in its responses. A lower temperature makes the model’s replies more deterministic and consistent, while a higher temperature introduces variability, allowing the model to produce varied answers to the same prompt.
Different models have different values for context length.
Select the Let the model decide checkbox to allow the model to determine when it has fulfilled the prompt request adequately.
Select Clear at the bottom of the Settings panel to return to system defaults.
Select the Let the model decide checkbox to allow the model to determine when it has fulfilled the prompt request adequately.
Select Clear at the bottom of the Settings panel to return to system defaults.