customers.csv):
-
Begin by importing libraries, and reading data into a Pandas DataFrame:
-
Then list column / variable names:
-
Summary statistics include minimum, maximum, mean, median, percentiles, and more:
value_counts function to show the number of items in each category, sorted
from largest to smallest. You can also set the ascending argument to True to display the list from smallest to largest.
Categorical variables
In statistics, a categorical variable may take on a limited number of possible values. Examples could include blood type, nation of origin, or ratings on a Likert scale. Like numbers, the possible values may have an order, such as fromdisagree to neutral to agree. The values cannot, however, be used for numerical operations such as addition or division.
Categorical variables tell other Python libraries how to handle the data, so those libraries can default to suitable statistical methods or plot types.
The following example converts the class variable of the Iris dataset from object to category.
agree, disagree, neither agree nor disagree, strongly agree, strongly disagree. The logical order could range from most negative to most positive as strongly disagree, disagree, neither agree nor disagree, agree, strongly agree.
Time series data visualization
The following code sample creates four series of random numbers over time, calculates the cumulative sums for each series over time, and plots them.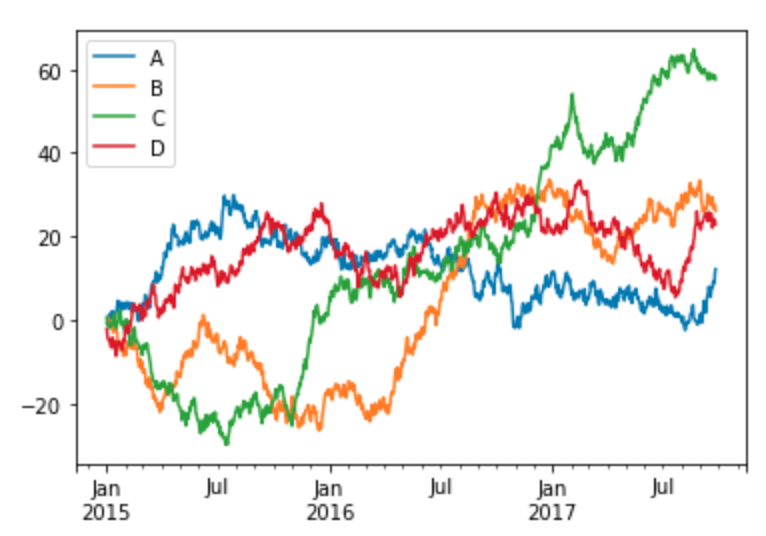
Histograms
This code sample plots a histogram of the sepal length values in the Iris data set: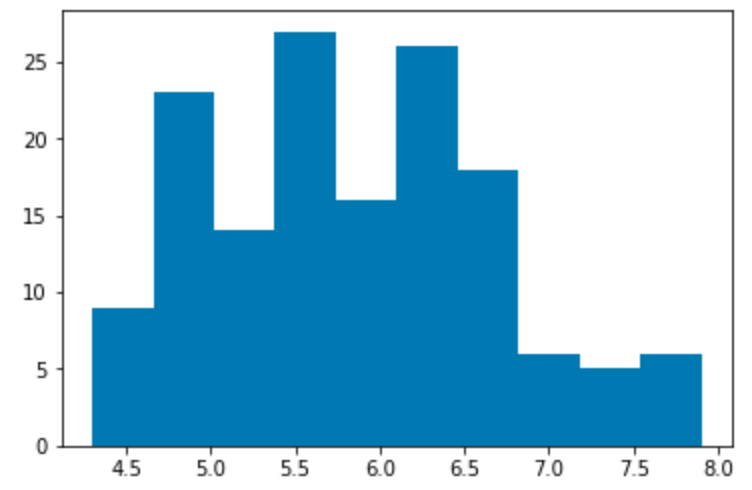
Bar charts
The following sample code produces a bar chart of the industries of customers in the customer data set.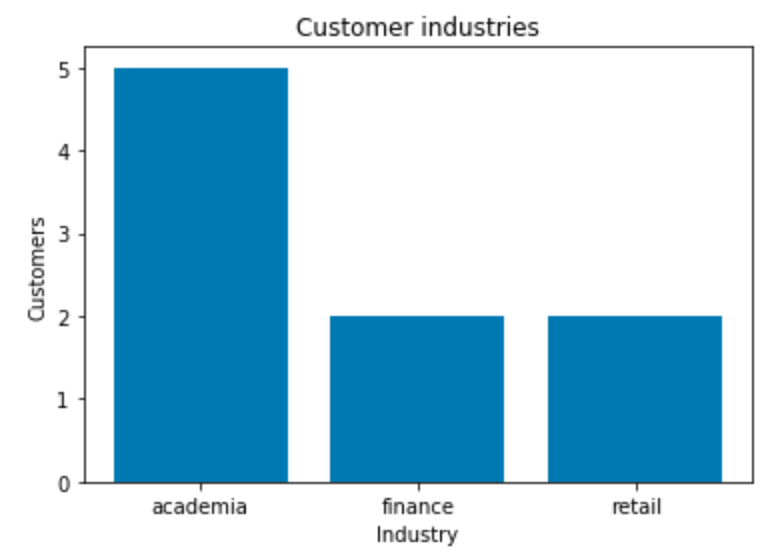
Scatter plots
This code sample makes a scatter plot of the sepal lengths and widths in the Iris data set: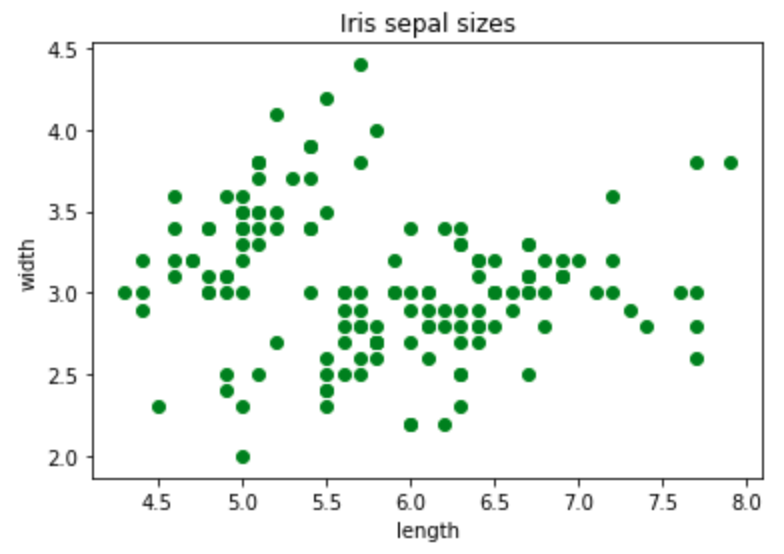
Sorting
To show the customer data set:| row | customer_id | title | industry |
|---|---|---|---|
| 0 | 1 | data scientist | retail |
| 1 | 2 | data scientist | academia |
| 2 | 3 | compiler optimizer | academia |
| 3 | 4 | data scientist | finance |
| 4 | 5 | compiler optimizer | academia |
| 5 | 6 | data scientist | academia |
| 6 | 7 | compiler optimizer | academia |
| 7 | 8 | data scientist | retail |
| 8 | 9 | compiler optimizer | finance |
| row | customer_id | title | industry |
|---|---|---|---|
| 1 | 2 | data scientist | academia |
| 2 | 3 | compiler optimizer | academia |
| 4 | 5 | compiler optimizer | academia |
| 5 | 6 | data scientist | academia |
| 6 | 7 | compiler optimizer | academia |
| 3 | 4 | data scientist | finance |
| 8 | 9 | compiler optimizer | finance |
| 0 | 1 | data scientist | retail |
| 7 | 8 | data scientist | retail |
| row | customer_id | title | industry |
|---|---|---|---|
| 2 | 3 | compiler optimizer | academia |
| 4 | 5 | compiler optimizer | academia |
| 6 | 7 | compiler optimizer | academia |
| 1 | 2 | data scientist | academia |
| 5 | 6 | data scientist | academia |
| 8 | 9 | compiler optimizer | finance |
| 3 | 4 | data scientist | finance |
| 0 | 1 | data scientist | retail |
| 7 | 8 | data scientist | retail |
sort_values function can also use the following arguments:
axisto sort either rows or columnsascendingto sort in either ascending or descending orderinplaceto perform the sorting operation in-place, without copying the data, which can save spacekindto use the quicksort, merge sort, or heapsort algorithmsna_positionto sort not a number (NaN) entries at the end or beginning
Grouping
customerdf.groupby('title')['customer_id'].count() counts the items in each
group, excluding missing values such as not-a-number values (NaN). Because
there are no missing customer IDs, this is equivalent to
customerdf.groupby('title').size().
groupby sorts the group keys. You can use the sort=False
option to prevent this, which can make the grouping operation faster.
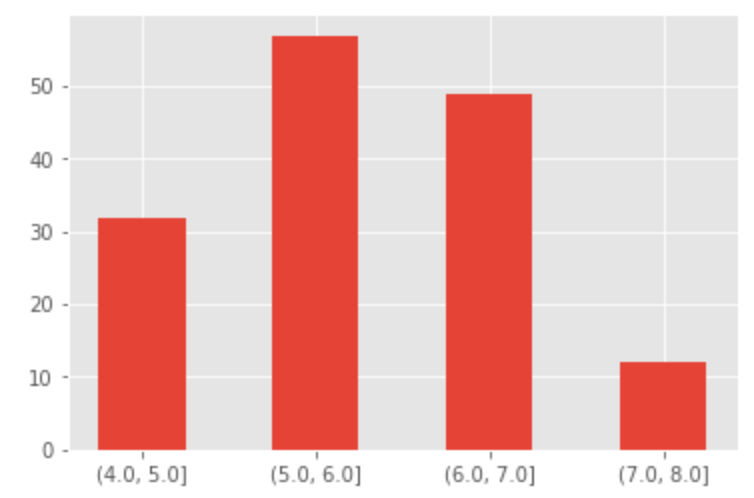
Binning
Binning or bucketing moves continuous data into discrete chunks, which can be used as ordinal categorical variables. You can divide the range of the sepal length measurements into four equal bins: